python入门 基本数据类型 sep 用来指定两个数据打印出来后中间的间隔符,例如
1 2 3 a="hello" b="world" print(a,b,sep=":")
格式化输出 1 2 3 4 5 6 7 8 9 10 name=input ("姓名:" ) age=input ("年龄:" ) job=input ("工作:" ) info= ''' --------info of %s---------- 姓名:%s 年龄:%s 工作:%s ''' %(name,name,age,job)print (info)
1 2 3 4 5 6 7 8 9 10 运行结果为: 姓名:英格科技 年龄:10 工作:学习 ---------info of 英格科技 姓名:英格科技 年龄:10 工作:学习
其中%s为占位符。
占位符 占位符
s,获取传入对象的str 方法的返回值,并将其格式化到指定位置
r,获取传入对象的repr 方法的返回值,并将其格式化到指定位置
c,整数:将数字转换成其unicode对应的值,10进制范围为 0 <= i <= 1114111(py27则只支持0-255);字符:将字符添加到指定位置
o,将整数转换成 八 进制表示,并将其格式化到指定位置
x,将整数转换成十六进制表示,并将其格式化到指定位置
d,将整数、浮点数转换成 十 进制表示,并将其格式化到指定位置
e,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(小写e)
E,将整数、浮点数转换成科学计数法,并将其格式化到指定位置(大写E)
f, 将整数、浮点数转换成浮点数表示,并将其格式化到指定位置(默认保留小数点后6位)
F,同上
g,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是e;)
G,自动调整将整数、浮点数转换成 浮点型或科学计数法表示(超过6位数用科学计数法),并将其格式化到指定位置(如果是科学计数则是E;)
%,当字符串中存在格式化标志时,需要用 %%表示一个百分号
字符串常用方法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 words = "beautiful is better than ugly." print (words.capitalize()) print (words.swapcase()) print (words.title()) a = "test" ret = a.center(20 ,"*" ) print (ret)ret = words.count("e" ,0 ,30 ) print (ret)a = "aisdjioadoiqwd12313assdj" print (a.startswith("a" ))print (a.endswith("j" ))print (a.startswith('sdj' ,2 ,5 ))print (a.endswith('ado' ,7 ,10 ))print (a.find('sdj' ,1 ,10 )) print (a.index('sdj' ,1 ,10 )) ret = words.split(' ' ) print (ret)ret = words.rsplit(' ' ,2 ) print (ret)print ('{} {} {}' .format ('aaron' ,18 ,'teacher' ))print ('{1} {0} {1}' .format ('aaron' ,18 ,'teacher' ))print ('{name} {age} {job}' .format (job='teacher' ,name='aaron' ,age=18 ))a = '****asdasdasd********' print (a.strip('*' ))print (a.lstrip('*' ))print (a.rstrip('*' ))print (words.replace('e' ,'a' ,2 )) print (words.isalnum()) print (words.isalpha()) print (words.isdigit())
四大重要数据类型 元祖 tuple 元组被称为只读列表,即数据可以被查询,但不能被修改。
tuple其实不可变的是地址空间,如果地址空间里存的是可变的数据类型的话,比如列表就是可变的
列表 list 增 1 2 3 4 5 6 7 8 9 li = [1 ,'a' ,2 ,'d' ,4 ] li.insert(0 ,22 ) print (li)li.append('ddd' ) print (li)li.extend(['q,a,w' ]) print (li)li.extend(['q,a,w' ,'das' ]) print (li)
1 2 3 4 [22 , 1 , 'a' , 2 , 'd' , 4 ] [22 , 1 , 'a' , 2 , 'd' , 4 , 'ddd' ] [22 , 1 , 'a' , 2 , 'd' , 4 , 'ddd' , 'q,a,w' ] [22 , 1 , 'a' , 2 , 'd' , 4 , 'ddd' , 'q,a,w' , 'q,a,w' , 'das' ]
删 1 2 3 4 5 6 7 8 9 li = [1 ,'a' ,2 ,'d' ,4 ,5 ,'f' ] a = li.pop(1 ) print (a)del li[1 :3 ] print (li)li.remove('f' ) print (li)li.clear() print (li)
1 2 3 4 a [1 , 4 , 5 , 'f' ] [1 , 4 , 5 ] []
改 1 2 3 4 5 li = [1 ,'a' ,2 ,'d' ,4 ,5 ,'f' ] li[1 ] = 'aaa' print (li)li[2 :3 ] = [3 ,'e' ] print (li)
1 2 [1 , 'aaa' , 2 , 'd' , 4 , 5 , 'f' ] [1 , 'aaa' , 3 , 'e' , 'd' , 4 , 5 , 'f' ]
其他操作 1 2 3 4 5 6 7 li = [1 ,2 ,4 ,5 ,4 ,2 ,4 ] print (li.count(4 )) print (li.index(2 )) li.sort() print (li)li.reverse() print (li)
1 2 3 4 3 1 [1 , 2 , 2 , 4 , 4 , 4 , 5 ] [5 , 4 , 4 , 4 , 2 , 2 , 1 ]
字典dict 字典是python中唯一的映射类型,采用键值对(key-value)的形式存储数据。python对key进行哈希函数运算,根据计算的结果决定value的存储地址,所以字典是无序存储的,且key必须是可哈希的。可哈希表示key必须是不可变类型,如:数字、字符串、元组。
从python3.6以后字典就是有顺序的了
参考博客
https://www.cnblogs.com/xieqiankun/p/python_dict.html
增 1 2 3 4 5 6 7 8 9 10 11 dic = {"age" :18 , "name" :"aaron" } dic['li' ] = ["a" ,"b" ,"c" ] print (dic)dic.setdefault('k' ,'v' ) print (dic)dic.setdefault('k' ,'v1' ) print (dic)
删 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 dic = {"age" :18 , "name" :"aaron" } dic_pop = dic.pop('age' ) print (dic_pop)dic_pop = dic.pop('sex' ,'查无此项' ) print (dic_pop)dic['age' ] = 18 print (dic)del dic['name' ]print (dic)dic['name' ] = 'demo' dic_pop = dic.popitem() print (dic_pop)dic_clear = dic.clear() print (dic,dic_clear)
改 1 2 3 4 5 6 7 8 9 dic = {"age" :18 , "name" :"aaron" , 'sex' :'male' } dic2 = {"age" :30 , "name" :'demo' } dic2.update(dic) print (dic2)dic2['age' ] = 30 print (dic2)
查 1 2 3 4 5 6 7 8 dic = {"age" :18 , "name" :"aaron" , 'sex' :'male' } value = dic['name' ] print (value)value = dic.get('abc' ,'查无此项' ) print (value)
其他操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 dic = {"age" :18 , "name" :"aaron" , 'sex' :'male' } for i in dic.items(): print (i) for key,value in dic.items(): print (key,value) for i in dic: print (i) keys = dic.keys() print (keys,type (keys))value = dic.values() print (value,type (value))
集合set 集合是无序 的,不重复 ,确定性 的数据集合,它里面的元素是可哈希的(不可变类型),但是集合本身是不可哈希(所以集合做不了字典的键)的。以下是集合最重要的两点:
去重,把一个列表变成集合,就自动去重了。
关系测试,测试两组数据之前的交集、差集、并集等关系。
创建集合 1 2 3 4 set1 = set ({1 ,2 ,'barry' }) set2 = {1 ,2 ,'barry' } print (set1,set2)
集合的增 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 set1 = {'abc' ,'def' ,123 ,'asdas' } 比如整型、浮点型、元组、字符串 set1.add('qwer' ) print (set1)set1.update('A' ) print (set1)set1.update('哈哈哈' ) print (set1)set1.update([1 ,2 ,3 ]) print (set1)
集合的删 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 set1 = {'abc' ,'def' ,123 ,'asdas' } set1.remove('abc' ) print (set1)set1.pop() print (set1)set1.clear() print (set1)del set1print (set1)
集合的其他操作 交集(& 或者 intersection) 取出两个集合共有的元素
1 2 3 4 5 6 7 8 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } print (set1 & set2)print (set1.intersection(set2))
并集(| 或者 union) 合并两个集合的所有元素
1 2 3 4 5 6 7 8 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } print (set1 | set2)print (set2.union(set1))
差集(- 或者 difference) 第一个集合去除二者共有的元素
1 2 3 4 5 6 7 8 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } print (set1 - set2)print (set1.difference(set2))
反交集 (^ 或者 symmetric_difference) 先合并,再去除共有元素
1 2 3 4 5 6 7 8 set1 = {1 ,2 ,3 ,4 ,5 } set2 = {3 ,4 ,5 ,6 ,7 } print (set1 ^ set2)print (set1.symmetric_difference(set2))
子集与超集 当一共集合的所有元素都在另一个集合里,则称这个集合是另一个集合的子集,另一个集合是这个集合的超集
1 2 3 4 5 6 7 8 set1 = {1 ,2 ,3 } set2 = {1 ,2 ,3 ,4 ,5 ,6 } print (set1 < set2)print (set1.issubset(set2)) print (set2 > set1)print (set2.issuperset(set1))
frozenset不可变集合,让集合变成不可变类型 1 2 3 4 5 6 set1 = {1 ,2 ,3 ,4 ,5 ,6 } s = frozenset (set1) print (s,type (s))s.add(7 )
循环中止语句 break 用于完全结束一个循环,跳出循环体执行循环后面的语句
continue 和 break 有点类似,区别在于 continue 只是终止本次循环,接着还执行后面的循环,break 则完全终止循环
while … else ..
while 后面的 else 作用是指,当 while 循环正常执行完,中间没有被 break 中止的话,就会执行 else 后面的语句
其他(for,enumerate,range) for循环:用户按照顺序循环可迭代对象的内容。
1 2 3 4 5 6 7 8 9 10 11 12 s = '先帝创业未半而中道崩殂,今天下三分,益州疲弊,此诚危急存亡之秋也。' for i in s: print (i) li = ['甲' ,'乙' ,'丙' ,'丁' ] for i in li: print (i) dic = {'a' :1 ,'b' :2 ,'c' :3 } for k,v in dic.items(): print (k,v)
enumerate:枚举,对于一个可迭代的(iterable)/可遍历的对象(如列表、字符串),enumerate将其组成一个索引序列,利用它可以同时获得索引和值。
1 2 3 4 5 6 7 8 9 10 11 12 li = ['甲' ,'乙' ,'丙' ,'丁' ] for i in li: print (i) for i in enumerate (li): print (i) for index,value in enumerate (li): print (index,value) for index,value in enumerate (li,100 ): print (index,value)
range:指定范围,生成指定数字。
1 2 3 4 5 6 7 8 for i in range (1 ,10 ): print (i) for i in range (1 ,10 ,2 ): print (i) for i in range (10 ,1 ,-2 ): print (i)
操作文件中的函数/方法
序号
函数/方法
说明
01
open
打开文件,并且返回文件操作对象
02
read
将文件内容读取到内存
03
write
将指定内容写入文件
04
close
关闭文件
open 函数负责打开文件,并且返回文件对象read/write/close 三个方法都需要通过 文件对象 来调用open函数:
第一个参数是文件名(文件名区分大小写),第二个参数是打开方式;
如果文件存在返回文件操作对象;
如果文件不存在抛出异常
read方法:可以一次性读入并返回文件的所有内容;
close方法:负责关闭文件;
文件打开方式
访问方式
说明
r
以只读 方式打开文件。文件的指针将会放在文件的开头,这是默认模式 。如果文件不存在,抛出异常
w
以只写 方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件
a
以追加 方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入
r+
以读写 方式打开文件。文件的指针将会放在文件的开头。如果文件不存在,抛出异常
w+
以读写 方式打开文件。如果文件存在会被覆盖。如果文件不存在,创建新文件
a+
以读写 方式打开文件。如果该文件已存在,文件指针将会放在文件的结尾。如果文件不存在,创建新文件进行写入
以bytes类型操作的读写,写读,写读模式
r+b
读写【可读,可写】
w+b
写读【可写,可读】
a+b
写读【可写,可读】
对于非文本文件,我们只能使用b模式,”b”表示以字节的方式操作(而所有文件也都是以字节的形式存储的,使用这种模式无需考虑文本文件的字符编码、图片文件的jgp格式、视频文件的avi格式)
rb wb ab
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
频繁的移动文件指针,会影响文件的读写效率,开发中更多的时候会以 只读、只写 的方式来操作文件.
按行读取文件内容
read方法默认会把文件的所有内容一次性读取到内存
readline方法可以一次读取一行内容;
方法执行后,文件指针移动到下一行,准备再次读取;
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 file1 = open ("README.txt" ) i = 1 while True : text1 = file1.readline().strip() if text1: print ("这是第%s行内容" % i) i += 1 print (text1) else : break file1.close() file2 = open ("README.txt" ) for i in file2.readlines(): print (i.strip()) file2.close()
with结构 把上面按行读取文件内容的代码使用with重新组织一下
1 2 3 4 5 6 7 8 9 with open ("README.txt" ) as file1: while True : text1 = file1.readline().strip() if text1: print ("这是第%s行内容" % i) i += 1 print (text1) else : break
close()在操作完毕文件后,一定要记住f.close(),推荐操作方式:使用with关键字来帮我们管理上下文
1 2 3 with open ('a.txt' ,'r' ) as read_f,open ('b.txt' ,'w' ) as write_f: data=read_f.read() write_f.write(data)
常用的操作方法 read(3):
文件打开方式为文本模式时,代表读取3个字符
文件打开方式为b模式时,代表读取3个字节
其余的文件内光标移动都是以字节为单位的如:seek,tell,truncate
注意:
seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果。
案例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 db={} info= ''' =======欢迎登录====== 1.登录 2.注册 3.退出 ''' while True : with open ('sql.txt' , 'r' , encoding='utf-8' ) as f: data = f.readlines() for i in data: ret=i.strip().split('|' ) db[ret[0 ]]=ret[1 ] print (info) num=input ("请输入你的选择:" ) if (num=='1' ): username=input ("请输入用户名:" ) if username in db: password=input ("请输入你的密码:" ) if password==db[username]: print ("登录成功" ) break else : print ("密码错误" ) else : print ("用户不存在" ) elif num == '2' : username=input ("请输入你的用户名:" ) if username in db: print ("用户已存在" ) else : password=input ("请输入密码:" ) with open ('sql.txt' ,'a+' ,encoding='utf-8' ) as f: f.write(username+'|' +password+ '\n' ) print (f"注册成功,你的账号密码是{username,password} " ) elif num=='3' : exit()
python面向函数 命名空间和作用域 代码在运行伊始,创建的存储“变量名与值的关系”的空间叫做全局命名空间; 在函数的运行中开辟的临时的空间叫做局部命名空间。
命名空间一共分为三种:
取值顺序:
在局部调用:局部命名空间->全局命名空间->内置命名空间
在全局调用:全局命名空间->内置命名空间
作用域
全局作用域:包含内置名称空间、全局名称空间,在整个文件的任意位置都能被引用、全局有效
局部作用域:局部名称空间,只能在局部范围内生效
globals和locals方法 1 2 3 4 5 6 7 8 9 10 print (globals ())print (locals ())def func (): a = 12 b = 20 print (globals ()) print (locals ()) func()
global 关键字
声明一个全局变量。
在局部作用域想要对全局作用域的全局变量进行修改时,需要用到 global(限于字符串,数字)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def func (): global a a = 3 func() print (a)count = 1 def search (): global count count = 2 search() print (count)
对可变数据类型(list,dict,set)可以直接引用不用通过global
1 2 3 4 5 6 7 8 9 10 11 12 li = [1 ,2 ,3 ] dic = {'name' :'aaron' } def change (): li.append(4 ) dic['age' ] = 18 print (dic) print (li) change() print (dic)print (li)
nonlocal
不能修改全局变量。
在局部作用域中,对父级作用域(或者更外层作用域非全局作用域)的变量进行引用和修改,并且引用的哪层,从那层及以下此变量全部发生改变。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 def add_b (): b = 1 def do_global (): b = 10 print (b) def dd_nolocal (): nonlocal b b = b + 20 print (b) dd_nolocal() print (b) do_global() print (b) add_b()
函数参数 带参数的函数
1 2 3 4 5 6 7 8 def my_len (s ): length = 0 for i in s: length += 1 return length ret = my_len('hello world!' ) print (ret)
实际的要交给函数的内容,简称实参。 在定义函数的时候它只是一个形式,表示这里有一个参数,简称形参。
按照位置传值:位置参数
1 2 3 4 5 6 def maxnumber (x,y ): the_max = x if x > y else y return the_max ret = maxnumber(10 ,20 ) print (ret)
按照关键字传值:关键字参数。
1 2 3 4 5 6 def maxnumber (x,y ): the_max = x if x > y else y return the_max ret = maxnumber(y = 10 ,x = 20 ) print (ret)
位置、关键字形式混着用:混合传参。
1 2 3 4 5 6 def maxnumber (x,y ): the_max = x if x > y else y return the_max ret = maxnumber(10 ,y = 20 ) print (ret)
位置参数必须在关键字参数的前面 对于一个形参只能赋值一次
默认参数。
1 2 3 4 5 def stu_info (name,age = 18 ): print (name,age) stu_info('aaron' ) stu_info('song' ,50 )
默认参数是一个可变数据类型
1 2 3 4 5 6 def demo (a,l = [] ): l.append(a) print (l) demo('abc' ) demo('123' )
动态参数
1 2 3 4 5 6 7 def demo (*args,**kwargs ): print (args,type (args)) print (kwargs,type (kwargs)) demo('aaron' ,1 ,3 ,[1 ,3 ,2 ,2 ],{'a' :123 ,'b' :321 },country='china' ,b=1 )
闭包 1 2 3 4 5 6 7 8 def func (): name = '张三' def inner (): print (name) return inner f = func() f()
内部函数包含对外部作用域而非全剧作用域变量的引用,该内部函数称为闭包函数
用途:可以提前在函数中封住一些预设的数据或者属性
判断闭包函数的方法closure
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 def func (): name = 'aaron' def inner (): print (name) print (inner.__closure__) return inner f = func() f() name = 'aaron' def func (): def inner (): print (name) print (inner.__closure__) return inner f = func() f() def wrapper (): money = 1000 def func (): name = 'apple' def inner (): print (name,money) return inner return func f = wrapper() i = f() i() def func (a,b ): def inner (x ): return a*x + b return inner func1 = func(4 ,5 ) func2 = func(7 ,8 ) print (func1(5 ),func2(6 ))from urllib.request import urlopendef func (): content = urlopen('http://myip.ipip.net' ).read().decode('utf-8' ) def get_content (): return content return get_content code = func() content = code() print (content)content2 = code() print (content2)
装饰器 装饰一个带参数的函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import timedef timer (func ): def inner (a ): start = time.time() func(a) print (time.time() - start) return inner @timer def func1 (a ): time.sleep(1 ) print (a) func1('hello world' )
装饰一个带各种参数 的函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 import timedef timer (func ): def inner (*args,**kwargs ): start = time.time() func(args,kwargs) print (time.time() - start) return inner @timer def func1 (*args,**kwargs ): print (args,kwargs) func1('hello world' ,'abc' ,123 ,432 )
wraps装饰器 查看函数的相关信息,在加上装饰器后就失效了
1 2 3 4 5 6 def index (): '''这是一条注释信息''' print ('from index' ) print (index.__doc__) print (index.__name__)
导入wraps装饰器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 from functools import wrapsdef deco (func ): @wraps(func ) def inner (*args,**kwargs ): return func(*args,**kwargs) return inner @deco def index (): '''这是一条注释信息''' print ('from index' ) print (index.__doc__) print (index.__name__)
带参数的装饰器 加上一个outer函数,可以携带一个flag的值,然后控制装饰器是否生效
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def outer (flag ): def timer (func ): def inner (*args,**kwargs ): if flag: print ('函数开始执行' ) re = func(*args,**kwargs) if flag: print ('函数执行完毕' ) return re return inner return timer @outer(True def func (): print ('test' ) func()
开放封闭原则 一句话,软件实体应该是可扩展但是不可修改的。
装饰器完美的遵循了这个开放封闭原则
装饰器的主要功能和固定结构 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def outer (func ): def inner (*args,**kwargs ): '''执行函数之前要做的''' re = func(*args,**kwargs) '''执行函数之后要做的''' return re return inner from functools import wrapsdef outer (func ): @wraps(func ) def inner (*args,**kwargs ) '''执行函数之前要做的''' re = func(*args,**kwargs) '''执行函数之后要做的''' return re return inner
迭代器与生成器 迭代器 迭代是访问集合元素的一种方式。迭代器是一个可以记住遍历的位置的对象。迭代器对象从集合的第一个元素开始访问,直到所有的元素被访问完结束。迭代器只能往前不会后退。
1. 可迭代对象 我们已经知道可以对list、tuple、str等类型的数据使用for…in…的循环语法从其中依次拿到数据进行使用,我们把这样的过程称为遍历,也叫迭代 。
但是,是否是所有的数据类型都可以放到for…in…的语句中,然后每次从中取出一条数据供我们使用,供我们迭代吗?
1 2 3 for i in 100 : print (i)
2. 如何判断一个对象是否可以迭代 可以使用 isinstance() 判断一个对象是否是 Iterable 对象:
1 2 3 4 5 6 7 8 9 10 11 12 from collections.abc import Iterablel = [1 , 2 , 3 , 4 ] t = (1 , 2 , 3 , 4 ) d = {1 : 2 , 3 : 4 } s = {1 , 2 , 3 , 4 } print (isinstance (l, Iterable))print (isinstance (t, Iterable))print (isinstance (d, Iterable))print (isinstance (s, Iterable))
3._*iter*_函数与__next__函数 迭代器遵循迭代器协议:必须拥有iter方法和next方法。
list、tuple等都是可迭代对象,我们可以通过iter()函数获取这些可迭代对象的迭代器。然后我们可以对获取到的迭代器不断使用next()函数来获取下一条数据。iter()函数实际上就是调用了可迭代对象的__iter__方法。
1 2 3 4 5 6 7 8 9 10 11 l = [1 , 2 , 3 , 4 ] l_iter = l.__iter__() item = l_iter.__next__() print (item)item = l_iter.__next__() print (item)item = l_iter.__next__() print (item)item = l_iter.__next__() print (item)
将可迭代对象转化成迭代器。(可迭代对象.iter *()) 内部使用**next
1 2 3 4 5 6 7 8 9 10 l = [1 , 2 , 3 , 4 ] l_iter = l.__iter__() while True : try : item = l_iter.__next__() print (item) except StopIteration: break
通过上面的分析,我们已经知道,迭代器是用来帮助我们记录每次迭代访问到的位置,当我们对迭代器使用next()函数的时候,迭代器会向我们返回它所记录位置的下一个位置的数据。实际上,在使用next()函数的时候,调用的就是迭代器对象的__next__方法(Python3中是对象的__next__方法,Python2中是对象的next()方法)。所以,我们要想构造一个迭代器,就要实现它的__next__方法 。但这还不够,python要求迭代器本身也是可迭代的,所以我们还要为迭代器实现__iter__方法,而__iter__方法要返回一个迭代器,迭代器自身正是一个迭代器,所以迭代器的__iter__方法返回自身即可。
4.如何判断一个对象是否是迭代器 可以使用 isinstance() 判断一个对象是否是 Iterator 对象:
1 2 3 4 5 6 7 8 9 10 from collections.abc import Iteratorisinstance ([], Iterator)False isinstance (iter ([]), Iterator)True isinstance (iter ("abc" ), Iterator)True
生成器 初识生成器 Python中提供的生成器
生成器函数:常规函数定义,但是,使用yield语句而不是return语句返回结果。yield语句一次返回一个结果,在每个结果中间,挂起函数的状态,以便下次从它离开的地方继续执行
生成器表达式:类似于列表推导,但是,生成器返回按需产生结果的一个对象,而不是一次构建一个结果列表
生成器Generator
本质:迭代器(所以自带了iter 方法和next 方法,不需要我们去实现)
特点:惰性运算,开发者自定义
生成器函数 一个包含yield关键字的函数就是一个生成器函数。 yield可以为我们从函数中返回值,但是yield又不同于return,return的执行意味着程序的结束,调用生成器函数不会得到返回的具体的值,而是得到一个可迭代的对象。每一次获取这个可迭代对象的值,就能推动函数的执行,获取新的返回值。直到函数执行结束。
1 2 3 4 5 6 7 8 9 10 11 12 def genrator_func1 (): a = 1 print ('将a赋值' ) yield a b = 2 print ('将b赋值' ) yield b g1 = genrator_func1() print (g1,next (g1))print (next (g1))
总结
使用了yield关键字的函数不再是函数,而是生成器。(使用了yield的函数就是生成器)
yield关键字有两点作用:
保存当前运行状态(断点),然后暂停执行,即将生成器(函数)挂起
将yield关键字后面表达式的值作为返回值返回,此时可以理解为起到了return的作用
可以使用next()函数让生成器从断点处继续执行,即唤醒生成器(函数)
send send 获取下一个值的效果和next基本一致 只是在获取下一个值的时候,给上一yield的位置 传递一个数据 使用send的注意事项
第一次使用生成器的时候 是用next获取下一个值
最后一个yield不能接受外部的值
1 2 3 4 5 6 7 8 9 10 11 12 def generator (): print (123 ) content = yield 1 print ('欢迎来到' ,content) print (456 ) yield 2 g = generator() ret = g.__next__() print ('***' ,ret)ret = g.send('英格科技' ) print ('***' ,ret)
推导式 列表推导式 30以内所有能被3整除的数
1 2 multiples = [i for i in range (30 ) if i % 3 == 0 ] print (multiples)
30以内所有能被3整除的数的平方
1 2 3 4 5 def squared (x ): return x*x multiples = [squared(i) for i in range (30 ) if i % 3 == 0 ] print (multiples)
找到嵌套列表中名字含有两个及以上‘a’的所有名字
1 2 3 4 fruits = [['peach' ,'Lemon' ,'Pear' ,'avocado' ,'cantaloupe' ,'Banana' ,'Grape' ], ['raisins' ,'plum' ,'apricot' ,'nectarine' ,'orange' ,'papaya' ]] print ([name for lst in fruits for name in lst if name.count('a' ) >= 2 ])
字典推导式 将一个字典的key和value对调
1 2 3 4 dic1 = {'a' :1 ,'b' :2 } dic2 = {dic1[k]: k for k in dic1} print (dic2)
合并大小写对应的value值,将k统一成小写
1 2 3 4 dic1 = {'a' :1 ,'b' :2 ,'y' :1 , 'A' :4 ,'Y' :9 } dic2 = {k.lower():dic1.get(k.lower(),0 ) + dic1.get(k.upper(),0 ) for k in dic1.keys()} print (dic2)
集合推导式 计算列表中每个值的平方,自带去重功能
1 2 3 4 l = [1 ,2 ,3 ,4 ,1 ,-1 ,-2 ,3 ] squared = {x**2 for x in l} print (squared)
内置函数 字符串类型代码的执行 eval,exec,complie
1 2 3 4 5 6 7 8 ret = eval ('2 + 2' ) print (ret)n = 20 ret = eval ('n + 23' ) print (ret)eval ('print("Hello world")' )
1 2 3 4 5 6 s = ''' for i in range(5): print(i) ''' exec (s)
compile:将字符串类型的代码编译。代码对象能够通过exec语句来执行或者eval()进行求值。
参数source:字符串。即需要动态执行的代码段。
参数 filename:代码文件名称,如果不是从文件读取代码则传递一些可辨认的值。当传入了source参数时,filename参数传入空字符即可。
参数model:指定编译代码的种类,可以指定为 ‘exec’,’eval’,’single’。当source中包含流程语句时,model应指定为‘exec’;当source中只包含一个简单的求值表达式,model应指定为‘eval’;当source中包含了交互式命令语句,model应指定为’single’。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 code1 = 'for i in range(5): print(i)' compile1 = compile (code1,'' ,'exec' ) exec (compile1)code2 = '1 + 2 + 3' compile2 = compile (code2,'' ,'eval' ) eval (compile2)code3 = 'name = input("please input you name: ")' compile3 = compile (code3,'' ,'single' ) exec (compile3)print (name)
有返回值的字符串形式的代码用eval,没有返回值的字符串形式的代码用exec,一般不用compile。
内存相关 hash id
hash:获取一个对象(可哈希对象:int,str,Bool,tuple)的哈希值。
1 2 3 4 5 6 7 print (hash (12322 ))print (hash ('123' ))print (hash ('arg' ))print (hash ('aaron' ))print (hash (True ))print (hash (False ))print (hash ((1 ,2 ,3 )))
1 2 print (id ('abc' ))print (id ('123' ))
文件操作相关 open:函数用于打开一个文件,创建一个 file 对象,相关的方法才可以调用它进行读写
迭代器生成器相关
range:函数可创建一个整数对象,一般用在 for 循环中。
next:内部实际使用了__next__方法,返回迭代器的下一个项目。
1 2 3 4 5 6 7 8 9 10 it = iter ([1 ,2 ,3 ,4 ,5 ,6 ]) while True : try : x = next (it) print (x) except StopIteration: break
iter:函数用来生成迭代器(讲一个可迭代对象,生成迭代器)。
1 2 3 4 5 6 7 8 9 10 from collections import Iterablefrom collections import Iteratorl = [1 ,2 ,3 ,4 ] print (isinstance (l,Iterable))print (isinstance (l,Iterator))l1 = iter (l) print (isinstance (l1,Iterable))print (isinstance (l1,Iterator))
基础数据类型相关 数字相关(14个) 数据类型 (4个):
bool :用于将给定参数转换为布尔类型,如果没有参数,返回 False。
int:函数用于将一个字符串或数字转换为整型。
1 2 3 4 print (int ())print (int ('12' ))print (int (3.6 ))print (int ('0100' ,base=2 ))
float:函数用于将整数和字符串转换成浮点数。
complex:函数用于创建一个值为 real + imag * j 的复数或者转化一个字符串或数为复数。如果第一个参数为字符串,则不需要指定第二个参数。
1 2 3 4 5 print (complex (1 ,2 ))print (complex (1 ))print (complex ("1" ))print (complex ("1+2j" ))
进制转换 (3个):
bin:将十进制转换成二进制并返回。
oct:将十进制转化成八进制字符串并返回。
hex:将十进制转化成十六进制字符串并返回。
1 2 3 print (bin (10 ),type (bin (10 )))print (oct (10 ),type (oct (10 )))print (hex (10 ),type (hex (10 )))
数学运算 (7):
abs:函数返回数字的绝对值。
divmod:计算除数与被除数的结果,返回一个包含商和余数的元组(a // b, a % b)。
round:保留浮点数的小数位数,默认保留整数。
pow:函数是计算x的y次方,如果z在存在,则再对结果进行取模,其结果等效于pow(x,y) %z)
1 2 3 4 5 6 7 8 9 10 print (abs (-5 )) print (divmod (7 ,2 )) print (round (7 /3 ,2 )) print (round (7 /3 )) print (round (3.32567 ,3 )) print (pow (2 ,3 )) print (pow (2 ,3 ,3 ))
sum:对可迭代对象进行求和计算(可设置初始值)。
min:返回可迭代对象的最小值(可加key,key为函数名,通过函数的规则,返回最小值)。
max:返回可迭代对象的最大值(可加key,key为函数名,通过函数的规则,返回最大值)。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 print (sum ([1 ,2 ,3 ]))print (sum ([1 ,2 ,3 ],100 ))print (min ([1 ,2 ,3 ]))ret = min ([1 ,2 ,3 ,-10 ],key=abs ) print (ret)dic = {'a' :3 ,'b' :2 ,'c' :1 } print (min (dic,key=lambda x:dic[x]))print (max ([1 ,2 ,3 ]))ret = max ([1 ,2 ,3 ,-10 ],key=abs ) print (ret)dic = {'a' :3 ,'b' :2 ,'c' :1 } print (max (dic,key=lambda x:dic[x]))
数据结构相关(24个) 列表和元祖 (2个)
list:将一个可迭代对象转化成列表(如果是字典,默认将key作为列表的元素)。
tuple:将一个可迭代对象转化成元祖(如果是字典,默认将key作为元祖的元素)。
1 2 3 4 5 6 7 8 9 10 11 12 13 l = list ((1 ,2 ,3 )) print (l)l = list ({1 ,2 ,3 }) print (l)l = list ({'k1' :1 ,'k2' :2 }) print (l)tu = tuple ((1 ,2 ,3 )) print (tu)tu = tuple ([1 ,2 ,3 ]) print (tu)tu = tuple ({'k1' :1 ,'k2' :2 }) print (tu)
相关内置函数 (2个)
reversed:将一个序列翻转,并返回此翻转序列的迭代器。
slice:构造一个切片对象,用于列表的切片。
1 2 3 4 5 6 7 8 9 10 ite = reversed (['a' ,2 ,4 ,'f' ,12 ,6 ]) for i in ite: print (i) l = ['a' ,'b' ,'c' ,'d' ,'e' ,'f' ,'g' ] sli = slice (3 ) print (l[sli])sli = slice (0 ,7 ,2 ) print (l[sli])
字符串相关 (9)
str:将数据转化成字符串。
format:与具体数据相关,用于计算各种小数,精算等。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 print (format ('test' ,'<20' ))print (format ('test' ,'>20' ))print (format ('test' ,'^20' ))print (format (192 ,'b' )) print (format (97 ,'c' )) print (format (11 ,'d' )) print (format (11 ,'o' )) print (format (11 ,'x' )) print (format (11 ,'X' )) print (format (11 ,'n' )) print (format (11 )) print (format (314159265 ,'e' )) print (format (314159265 ,'0.2e' )) print (format (314159265 ,'0.2E' )) print (format (3.14159265 ,'f' )) print (format (3.14159265 ,'0.10f' )) print (format (3.14e+10000 ,'F' )) print (format (0.00003141566 ,'.1g' ))print (format (0.00003141566 ,'.2g' ))print (format (3.1415926777 ,'.1g' ))print (format (3.1415926777 ,'.2g' ))print (format (3141.5926777 ,'.2g' ))print (format (0.00003141566 ,'.1n' )) print (format (0.00003141566 ))
1 2 3 4 5 6 7 8 9 10 s = '你好' bs = s.encode('utf-8' ) print (bs)s1 = bs.decode('utf-8' ) print (s1)bs = bytes (s,encoding='utf-8' ) print (bs)b = '你好' .encode('gbk' ) b1 = b.decode('gbk' ) print (b1.encode('utf-8' ))
bytearry:返回一个新字节数组。这个数组里的元素是可变的,并且每个元素的值范围: 0 <= x < 256。
1 2 3 4 5 6 7 ret = bytearray ('aaron' ,encoding='utf-8' ) print (id (ret))print (ret)print (ret[0 ])ret[0 ] = 65 print (ret)print (id (ret))
memoryview: 通过内存查看数据,是指对支持缓冲区协议的数据进行包装,在不需要复制对象基础上允许Python代码访问。
1 2 3 4 5 ret = memoryview (bytes ('你好' ,encoding='utf-8' )) print (len (ret))print (ret)print (bytes (ret[:3 ]).decode('utf-8' ))print (bytes (ret[3 :]).decode('utf-8' ))
ord:输入字符找该字符编码的位置
chr:输入位置数字找出其对应的字符
ascii:是ascii码中的返回该值,不是就返回/u…
1 2 3 4 5 6 7 8 9 10 11 print (ord ('a' ))print (ord ('中' ))print (chr (97 ))print (chr (20013 ))print (ascii ('a' ))print (ascii ('中' ))
1 2 3 4 5 6 name = 'aaron' print ('Hello %r' %name)str1 = '{"name":"aaron"}' print (repr (str1))print (str1)
数据集合 (3个)
dict:创建一个字典。
set:创建一个集合。
frozenset:返回一个冻结的集合,冻结后集合不能再添加或删除任何元素 。
相关内置函数 (8个)
len:返回一个对象中元素的个数。
sorted:对所有可迭代的对象进行排序操作。
1 2 3 4 l = [('a' ,1 ),('c' ,3 ),('d' ,4 ),('b' ,2 )] print (sorted (l,key=lambda x:x[1 ]))print (sorted (l,key=lambda x:x[1 ],reverse=True ))
enumerate: 用于将一个可遍历的数据对象(如列表、元组或字符串)组合为一个索引序列,同时列出数据和数据下标,一般用在 for 循环当中。
1 2 3 4 5 6 7 print (enumerate ([1 ,2 ,3 ]))for i in enumerate ([1 ,2 ,3 ]): print (i) for i in enumerate ([1 ,2 ,3 ],100 ): print (i)
all:可迭代对象中,全都是True才是True
any:可迭代对象中,有一个True 就是True
1 2 print (all ([1 ,2 ,True ,0 ]))print (any ([1 ,'' ,0 ]))
zip:函数用于将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的列表。如果各个可迭代对象的元素个数不一致,则返回列表长度与最短的对象相同。
1 2 3 4 5 l1 = [1 ,2 ,3 ,] l2 = ['a' ,'b' ,'c' ,5 ] l3 = ('*' ,'**' ,(1 ,2 ,3 )) for i in zip (l1,l2,l3): print (i)
filter:用于过滤序列,过滤掉不符合条件的元素,返回由符合条件元素组成的新列表。
1 2 3 4 5 6 def func (x ): return x%2 == 0 ret = filter (func,[1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ,9 ,10 ]) print (ret)for i in ret: print (i)
map:会根据提供的函数对指定序列做映射。Python 3.x 返回迭代器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def square (x ): return x**2 ret1 = map (square,[1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ]) ret2 = map (lambda x:x ** 2 ,[1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ]) ret3 = map (lambda x,y : x+y,[1 ,2 ,3 ,4 ,5 ,6 ,7 ,8 ],[8 ,7 ,6 ,5 ,4 ,3 ,2 ,1 ]) for i in ret1: print (i,end=' ' ) print ('' )for i in ret2: print (i,end=' ' ) print ('' )for i in ret3: print (i,end=' ' )
递归与二分法查找 初识递归
递归的定义——在一个函数里再调用这个函数本身
为了防止递归无限进行,通常我们会指定一个退出条件
递归的最大深度——997
1 2 3 4 5 def foo (n ): print (n) n += 1 foo(n) foo(1 )
997是python为了我们程序的内存优化所设定的一个默认值,我们当然还可以通过一些手段去修改它。
1 2 3 4 5 6 7 8 9 import sysprint (sys.setrecursionlimit(10000 ))def foo (n ): print (n) n += 1 foo(n) foo(1 )
汉诺塔问题 汉诺塔小游戏: https://apps.fuyeor.com/zh-cn/games/hanoi/
从左到右 A B C 柱 大盘子在下, 小盘子在上, 借助B柱将所有盘子从A柱移动到C柱, 期间只有一个原则: 大盘子只能在小盘子的下面.
我们只需要考虑如果有64层,先将A柱上的63层移动到B柱上,然后将A柱的第64个移动到C柱上,然后将B柱上的63层移动到C柱上即可。
那怎么把63层都移到B柱上,这个问题可以用上面相同的方法解决。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 def move (n,a,b,c ): ''' n代表层数 a代表原来的柱子 b代表空闲的柱子 c代表目的柱子 ''' if n == 1 : print (a,'->' ,c) else : move(n-1 ,a,c,b) print (a,'->' ,c) move(n-1 ,b,a,c) n = int (input ('请输入汉诺塔的层数:' )) move(n,'A' ,'B' ,'C' )
递归实现三级菜单
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 menu = { '山东' : { '青岛' : ['四方' , '黄岛' , '崂山' , '李沧' , '城阳' ], '济南' : ['历城' , '槐荫' , '高新' , '长青' , '章丘' ], '烟台' : ['龙口' , '莱山' , '牟平' , '蓬莱' , '招远' ] }, '江苏' : { '苏州' : ['沧浪' , '相城' , '平江' , '吴中' , '昆山' ], '南京' : ['白下' , '秦淮' , '浦口' , '栖霞' , '江宁' ], '无锡' : ['崇安' , '南长' , '北塘' , '锡山' , '江阴' ] }, '浙江' : { '杭州' : ['西湖' , '江干' , '下城' , '上城' , '滨江' ], '宁波' : ['海曙' , '江东' , '江北' , '镇海' , '余姚' ], '温州' : ['鹿城' , '龙湾' , '乐清' , '瑞安' , '永嘉' ] }, '安徽' : { '合肥' : ['蜀山' , '庐阳' , '包河' , '经开' , '新站' ], '芜湖' : ['镜湖' , '鸠江' , '无为' , '三山' , '南陵' ], '蚌埠' : ['蚌山' , '龙子湖' , '淮上' , '怀远' , '固镇' ] }, '广东' : { '深圳' : ['罗湖' , '福田' , '南山' , '宝安' , '布吉' ], '广州' : ['天河' , '珠海' , '越秀' , '白云' , '黄埔' ], '东莞' : ['莞城' , '长安' , '虎门' , '万江' , '大朗' ] }, '测试' : {} } def threeLM (dic ): while True : for k in dic: print (k) key = input ('input>>' ).strip() if key == 'b' or key == 'q' : return key elif key in dic.keys() and dic[key]: ret = threeLM(dic[key]) if ret == 'q' : return 'q' threeLM(menu)
二分查找法 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 l = [2 ,3 ,5 ,10 ,15 ,16 ,18 ,22 ,26 ,30 ,32 ,35 ,41 ,42 ,43 ,55 ,56 ,66 ,67 ,69 ,72 ,76 ,82 ,83 ,88 ] num = 0 for i in l: num += 1 if i == 66 : print (l.index(i)) break print (num)递归:初级 def func (l,aim ): mid = (len (l)-1 )//2 if l: if aim > l[mid]: func(l[mid+1 :],aim) elif aim < l[mid]: func(l[:mid],aim) elif aim == l[mid]: print ("找到了" ,mid) else : print ('找不到' ) func(l,66 ) func(l,6 ) 递归:高级 def search (num,l,start=None ,end=None ): start = start if start else 0 end = len (l)-1 if end is None else end mid = (end - start)//2 + start if start > end: return None elif l[mid] > num : return search(num,l,start,mid-1 ) elif l[mid] < num: return search(num,l,mid+1 ,end) elif l[mid] == num: return mid ret = search(18 ,l) print (ret)
模块和包 为什么使用模块 实现代码和功能的复用
import 自定义模块my_module.py 文件名my_module.py,模块名my_module
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 print ('from the my_module.py' )money = 100 def read1 (): print ('my_module->read1->money' ,money) def read2 (): print ('my_module->read2 calling read1' ) read1() def change (): global money money=0
模块可以包含可执行的语句和函数的定义,这些语句的目的是初始化模块,它们只在模块名第一次遇到导入import语句时才执行(import语句是可以在程序中的任意位置使用的,且针对同一个模块很import多次,为了防止你重复导入。 python的优化手段是:第一次导入后就将模块名加载到内存了,后续的import语句仅是对已经加载大内存中的模块对象增加了一次引用,不会重新执行模块内的语句)
1 2 3 4 5 6 7 8 import my_moduleimport my_moduleimport my_moduleimport my_moduleimport sysprint (sys.modules)
每个模块都是一个独立的名称空间,定义在这个模块中的函数,把这个模块的名称空间当做全局名称空间,这样我们在编写自己的模块时,就不用担心我们定义在自己模块中全局变量会在被导入时,与使用者的全局变量冲突
1 2 3 4 5 6 7 8 9 10 11 12 13 14 import my_modulemoney=10 print (my_module.money)import my_moduledef read1 (): print ('=========' ) my_module.read1() import my_modulemoney = 1 my_module.change() print (money)print (my_module.money)
总结:首次导入模块my_module时会做三件事:
为源文件(my_module模块)创建新的名称空间
在新创 建的命名空间中执行模块中包含的代码
创建名字my_module来引用该命名空间
为模块名起别名,相当于m1=1;m2=m1 1 2 3 import my_module as mmprint (mm.money)
示范用法:
有两中sql模块mysql和oracle,根据用户的输入,选择不同的sql功能
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 def sqlparse (): print ('from mysql sqlparse' ) def sqlparse (): print ('from oracle sqlparse' ) db_type=input ('>>: ' ) if db_type == 'mysql' : import mysql as db elif db_type == 'oracle' : import oracle as db db.sqlparse()
在一行导入多个模块 from … import … 对比import my_module,会将源文件的名称空间’my_module’带到当前名称空间中,使用时必须是my_module.名字的方式
而from 语句相当于import,也会创建新的名称空间,但是将my_module中的名字直接导入到当前的名称空间中,在当前名称空间中,直接使用名字就可以了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 from my_module import read1,read2money = 1000 read1() from my_module import read1,read2money = 1000 def read1 (): print ('*' *10 ) read2() from my_module import read1,read2money = 1000 def read1 (): print ('*' *10 ) read1() from my_module import read1 as readread()
from mymodule import * 把my_module中所有的不是以下划线( )开头的名字都导入到当前位置 大部分情况下我们的python程序不应该使用这种导入方式,因为*你不知道你导入什么名字,很有可能会覆盖掉你之前已经定义的名字。而且可读性极其的差,在交互式环境中导入时没有问题。
在my_module.py中新增一行
1 2 3 4 5 6 7 8 9 10 ..... __all__ = ['money' ,'read1' ] from my_module import *print (money)read1() read2()
注意:如果my_module.py中的名字前加_,即_money,则from my_module import *,则_money不能被导入
编写好的一个python文件可以有两种用途:
脚本,一个文件就是整个程序,用来被执行
模块,文件中存放着一堆功能,用来被导入使用
python为我们内置了全局变量__name__,
当文件被当做脚本执行时:__name__ 等于'__main__'
当文件被当做模块导入时:__name__等于模块名
作用:用来控制.py文件在不同的应用场景下执行不同的逻辑(或者是在模块文件中测试代码)
if __name__ == '__main__':
1 2 3 4 5 6 7 8 9 10 11 12 13 def fib (n ): a, b = 0 , 1 while b < n: print (b, end=',' ) a, b = b, a+b print () if __name__ == "__main__" : print (__name__) num = input ('num :' ) fib(int (num)) print (globals ())
模块的搜索路径 模块的查找顺序是:内存中已经加载的模块->自建模块->sys.path路径中包含的模块
在第一次导入某个模块时(比如my_module),会先检查该模块是否已经被加载到内存中(当前执行文件的名称空间对应的内存),如果有则直接引用 ps:python解释器在启动时会自动加载一些模块到内存中,可以使用sys.modules查看
如果没有,解释器则会查找同名的内建模块
如果还没有找到就从sys.path给出的目录列表中依次寻找my_module.py文件。
注意:自定义的模块名不应该与系统内置模块重名
编译python文件 为了提高加载模块的速度,python解释器会在__pycache__目录中下缓存每个模块编译后的版本,格式为:module.version.pyc。通常会包含python的版本号。例如,在CPython3.3版本下,my*module.py模块会被缓存成\*_pycache**/my_module.cpython-33.pyc。这种命名规范保证了编译后的结果多版本共存。
包 包就是一个包含有__init__.py文件的文件夹,所以其实我们创建包的目的就是为了用文件夹将文件/模块组织起来
需要强调的是:
在python3中,即使包下没有__init__.py文件,import 包仍然不会报错,而在python2中,包下一定要有该文件,否则import 包报错
创建包的目的不是为了运行,而是被导入使用,记住,包只是模块的一种形式而已,包的本质就是一种模块
为何要使用包 包的本质就是一个文件夹,那么文件夹唯一的功能就是将文件组织起 来 随着功能越写越多,我们无法将所以功能都放到一个文件中,于是我们使用模块去组织功能,而随着模块越来越多,我们就需要用文件夹将模块文件组织起来,以此来提高程序的结构性和可维护性
注意事项
关于包相关的导入语句也分为import和from ... import ...两种,但是无论哪种,无论在什么位置,在导入时都必须遵循一个原则:凡是在导入时带点的,点的左边都必须是一个包,否则非法。可以带有一连串的点,如item.subitem.subsubitem,但都必须遵循这个原则。但对于导入后,在使用时就没有这种限制了,点的左边可以是包,模块,函数,类(它们都可以用点的方式调用自己的属性)。
import导入文件时,产生名称空间中的名字来源于文件,import 包,产生的名称空间的名字同样来源于文件,即包下的__init__.py,导入包本质就是在导入该文件
包A和包B下有同名模块也不会冲突,如A.a与B.a来自俩个命名空间
包的使用 示例文件
1 2 3 4 5 6 7 8 9 10 11 12 glance/ ├── __init__.py ├── api │ ├── __init__.py │ ├── policy.py │ └── versions.py ├── cmd │ ├── __init__.py │ └── manage.py └── db ├── __init__.py └── models.py
文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 def get (): print ('from policy.py' ) def create_resource (conf ): print ('from version.py: ' ,conf) def main (): print ('from manage.py' ) def register_models (engine ): print ('from models.py: ' ,engine)
使用import导入包 1 2 3 4 import glance.db.modelsglance.db.models.register_models('mysql' )
单独导入包名称时不会导入包中所有包含的所有子模块
1 2 import glanceglance.cmd.manage.main()
解决方法
1 2 3 4 5 from . import cmdfrom . import manage
使用from (具体的路径) import (具体的模块) 需要注意的是from后import导入的模块,必须是明确的一个不能带点,否则会有语法错误,如:from a import b.c是错误语法
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from glance.db import modelsfrom glance.db.models import register_modelsmodels.register_models('mysql' ) register_models('mysql' ) from glance.api import *` 想从包api中导入所有,实际上该语句只会导入包api下`__init__.py`文件中定义的名字,我们可以在这个文件中定义`__all__x = 10 def func (): print ('from api.__init.py' ) __all__=['x' ,'func' ,'policy' ] from glance.api import *func() print (x)policy.get()
绝对导入和相对导入
绝对导入:以glance作为起始
相对导入:用.或者..的方式最为起始(只能在一个包中使用,不能用于不同目录内)
绝对导入: 以执行文件的sys.path为起始点开始导入,称之为绝对导入
优点: 执行文件与被导入的模块中都可以使用
缺点: 所有导入都是以sys.path为起始点,导入麻烦
相对导入: 参照当前所在文件的文件夹为起始开始查找,称之为相对导入
符号: .代表当前所在文件的文件加,..代表上一级文件夹,…代表上一级的上一级文件夹
优点: 导入更加简单
缺点: 只能在导入包中的模块时才能使用 注意:
相对导入只能用于包内部模块之间的相互导入,导入者与被导入者都必须存在于一个包内
试图在顶级包之外使用相对导入是错误的,言外之意,必须在顶级包内使用相对导入,每增加一个.代表跳到上一级文件夹,而上一级不应该超出顶级包
常用模块 序列化模块 json 模块 提供了四个功能:dumps,dump,loads,load
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import jsondic = {'k1' :'v1' ,'k2' :'v2' ,'k3' :'v3' } str_dic = json.dumps(dic) print (type (str_dic),str_dic)dic2 = json.loads(str_dic) print (type (dic2),dic2)list_dic = [1 ,['a' ,'b' ,'c' ],3 ,{'k1' :'v1' ,'k2' :'v2' }] str_dic = json.dumps(list_dic) print (type (str_dic),str_dic)list_dic2 = json.loads(str_dic) print (type (list_dic2),list_dic2)
Skipkeys
1,默认值是False,如果dict的keys内的数据不是python的基本类型,2,设置为False时,就会报TypeError的错误。此时设置成True,则会跳过这类key,3,当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。
indent
是一个非负的整型,如果是0就是顶格分行显示,如果为空就是一行最紧凑显示,否则会换行且按照indent的数值显示前面的空白分行显示,这样打印出来的json数据也叫pretty-printed json
ensure_ascii
当它为True的时候,所有非ASCII码字符显示为\uXXXX序列,只需在dump时将ensure_ascii设置为False即可,此时存入json的中文即可正常显示。
separators
分隔符,实际上是(item_separator, dict_separator)的一个元组,默认的就是(‘,’,’:’);这表示dictionary内keys之间用“,”隔开,而KEY和value之间用“:”隔开。
sort_keys
将数据根据keys的值进行排序
1 2 3 4 5 import jsondata = {'name' :'英格科技' ,'job' :'学习' ,'age' :88 } json_dic2 = json.dumps(data,sort_keys=True ,indent=2 ,separators=(',' ,':' ),ensure_ascii=False ) print (json_dic2)
json.dump和json.load不常用,主要是针对文件操作进行序列化和反序列化
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import jsonwith open ('data.txt' ,'w' ,encoding="utf-8" ) as f: json.dump(data,f,sort_keys=True ,indent=2 ,separators=(',' ,':' ),ensure_ascii=False ) ----------------结果: { "age" :88 , "job" :"学习" , "name" :"英格科技" } import jsonwith open ('data.txt' ,'r' ,encoding="utf-8" ) as f: json_data = json.load(f) print (json_data) ---------------结果: <class 'dict' > {'age' : 88 , 'job' : '学习' , 'name' : '英格科技' }
pickle模块
json
用于字符串 和 python数据类型间进行转换
pickle
用于python特有的类型 和 python的数据类型间进行转换
pickle同样提供了四个功能:dumps,dump,loads,load
不仅可以序列化字典,列表…可以把python中任意的数据类型序列化
json模块和picle模块都有 dumps、dump、loads、load四种方法,而且用法一样。
不同的是json模块序列化出来的是通用格式,其它编程语言都认识,就是普通的字符串,
而picle模块序列化出来的只有python可以认识,其他编程语言不认识的,表现为乱码
不过picle可以序列化函数,但是其他文件想用该函数,在该文件中需要有该文件的定义(定义和参数必须相同,内容可以不同)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import pickledic = {'k1' :'v1' ,'k2' :'v2' ,'k3' :'v3' } str_dic = pickle.dumps(dic) print (str_dic)dic2 = pickle.loads(str_dic) print (dic2)import timestruct_time = time.localtime(time.time()) print (struct_time)f = open ('pickle_file' ,'wb' ) pickle.dump(struct_time,f) f.close() f = open ('pickle_file' ,'rb' ) struct_time2 = pickle.load(f) print (struct_time2.tm_year)
shelve模块 shelve只提供给我们一个open方法,是用key来访问的,使用起来和字典类似。
参考博客
https://www.cnblogs.com/sui776265233/p/9225164.html
1 2 3 4 5 6 7 8 9 import shelvef = shelve.open ('shelve_file' ) f['key' ] = {'int' :10 ,'str' :'hello' ,'float' :0.123 } f.close() f1 = shelve.open ('shelve_file' ) ret = f1['key' ] f1.close() print (ret)
这个模块有个限制,它不支持多个应用同一时间往同一个DB进行写操作。所以当我们知道我们的应用如果只进行读操作,我们可以让shelve通过只读方式打开DB
1 2 3 4 5 import shelvef1 = shelve.open ('shelve_file' ,flag='r' ) ret = f1['key' ] f1.close() print (ret)
由于shelve在默认情况下是不会记录待持久化对象的任何修改的,所以我们在shelve.open()时候需要修改默认参数,否则对象的修改不会保存。
1 2 3 4 5 6 7 8 9 10 11 import shelvef1 = shelve.open ('shelve_file' ) print (f1['key' ])f1['key' ]['k1' ] = 'v1' f1.close() f2 = shelve.open ('shelve_file' ,writeback=True ) print (f2['key' ])f2['key' ]['k1' ] = 'hello' f2.close()
使用shelve模块实现简单的数据库
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 import sys,shelvedef print_help (): '存储(增加)、查找、更新(修改)、循环打印、删除、退出、帮助' print ('The available commons are: ' ) print ('store : Stores information about a person' ) print ('lookup : Looks up a person from ID numbers' ) print ("update : Update a person's information from ID number" ) print ('print_all: Print all informations' ) print ("delete : Delete a person's information from ID number" ) print ('quit : Save changes and exit' ) print ('? : Print this message' ) def store_people (db ): pid = input ('Please enter a unique ID number: ' ) person = {} person['name' ] = input ('Please enter the name: ' ) person['age' ] = input ('Please enter the age: ' ) person['phone' ] = input ('Please enter the phone: ' ) db[pid] = person print ("Store information: pid is %s, information is %s" % (pid, person)) def lookup_people (db ): pid = input ('Please enter the number: ' ) field = input ('What would you like to know? (name, age, phone) ' ) if pid in db.keys(): value = db[pid][field] print ("Pid %s's %s is %s" % (pid, field, value)) else : print ('Not found this number' ) def update_people (db ): pid = input ('Please enter the number: ' ) field = input ('What would you like to update? (name, age, phone) ' ) newvalue = input ('Enter the new information: ' ) if pid in db.keys(): value = db[pid] value[field] = newvalue print ("Pid %s's %s update information is %s" % (pid, field, newvalue)) else : print ("Not found this number, can't update" ) def delete_people (db ): pid = input ('Please enter the number: ' ) if pid in db.keys(): del db[pid] print ("pid %s's information delete done" % pid) else : print ( "Not found this number, can't delete" ) def print_all_people (db ): print ( 'All information are: ' ) for key, value in db.items(): print (key, value) def enter_cmd (): cmd = input ('Please enter the cmd(? for help): ' ) cmd = cmd.strip().lower() return cmd def main (): database = shelve.open ('database201803.dat' , writeback=True ) try : while True : cmd = enter_cmd() if cmd == 'store' : store_people(database) elif cmd == 'lookup' : lookup_people(database) elif cmd == 'update' : update_people(database) elif cmd == 'print_all' : print_all_people(database) elif cmd == 'delete' : delete_people(database) elif cmd == '?' : print_help() elif cmd == 'quit' : return finally : database.close() if __name__ == '__main__' : main()
hashlib模块 Python的hashlib提供了常见的摘要算法,如MD5,SHA1等等
什么是摘要算法呢?摘要算法又称哈希算法、散列算法。它通过一个函数,把任意长度的数据转换为一个长度固定的数据串(通常用16进制的字符串表示)。
摘要算法就是通过摘要函数f()对任意长度的数据data计算出固定长度的摘要digest,目的是为了发现原始数据是否被人篡改过。
摘要算法之所以能指出数据是否被篡改过,就是因为摘要函数是一个单向函数,计算f(data)很容易,但通过digest反推data却非常困难。而且,对原始数据做一个bit的修改,都会导致计算出的摘要完全不同。
1 2 3 4 5 import hashlibmd5 = hashlib.md5() md5.update('how to use md5 in python hashlib?' .encode('utf-8' )) print (md5.hexdigest())
如果数据量很大,可以分块多次调用update(),最后计算的结果是一样的
1 2 3 4 5 6 import hashlibmd5 = hashlib.md5() md5.update('how to use md5 ' .encode('utf-8' )) md5.update('in python hashlib?' .encode('utf-8' )) print (md5.hexdigest())
MD5是最常见的摘要算法,速度很快,生成结果是固定的128 bit字节,通常用一个32位的16进制字符串表示。另一种常见的摘要算法是SHA1,调用SHA1和调用MD5完全类似
1 2 3 4 5 6 import hashlibsha1 = hashlib.sha1() sha1.update('how to use md5 ' .encode('utf-8' )) sha1.update('in python hashlib?' .encode('utf-8' )) print (sha1.hexdigest())
摘要算法的应用 任何允许用户登录的网站都会存储用户登录的用户名和口令。如何存储用户名和口令呢?方法是存到数据库表中
1 2 3 4 5 name | password michael | 123456 bob | abc999 alice | alice2008
如果使用md5来将保护密码那么就是这样
1 2 3 4 5 username | password michael | e10adc3949ba59abbe56e057f20f883e bob | 878 ef96e86145580c38c87f0410ad153 alice | 99 b1c2188db85afee403b1536010c2c9
有很多md5撞库工具,可以轻松的将简单密码给碰撞出来
所以,要确保存储的用户口令不是那些已经被计算出来的常用口令的MD5,这一方法通过对原始口令加一个复杂字符串来实现,俗称“加盐”
经过Salt处理的MD5口令,只要Salt不被黑客知道,即使用户输入简单口令,也很难通过MD5反推明文口令。
但是如果有两个用户都使用了相同的简单口令比如123456,在数据库中,将存储两条相同的MD5值,这说明这两个用户的口令是一样的。
如果假定用户无法修改登录名,就可以通过把登录名作为Salt的一部分来计算MD5,从而实现相同口令的用户也存储不同的MD5。
configparser模块 该模块适用于配置文件的格式与windows ini文件类似,可以包含一个或多个节(section),每个节可以有多个参数(键=值)。
常见的文档格式
1 2 3 4 5 6 7 8 9 10 11 12 [DEFAULT] ServerAliveInterval = 45 Compression = yes CompressionLevel = 9 ForwardX11 = yes [bitbucket.org] User = hg [topsecret.server.com] Port = 50022 ForwardX11 = no
使用python生成一个这样的文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import configparserconf = configparser.ConfigParser() conf['DEFAULT' ] = {'ServerAliveInterval' :'45' , 'Compression' :'yes' , 'CompressionLevel' :'9' , 'ForwardX11' :'yes' } conf['bitbucket.org' ] = {'User' :'hg' } conf['topsecret.server.com' ] = {'Port' :'50022' , 'ForwardX11' :'no' } with open ('config' ,'w' ) as config: conf.write(config)
查找
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import configparserconf = configparser.ConfigParser() conf['DEFAULT' ] = {'ServerAliveInterval' :'45' , 'Compression' :'yes' , 'CompressionLevel' :'9' , 'ForwardX11' :'yes' } conf['bitbucket.org' ] = {'User' :'hg' } conf['topsecret.server.com' ] = {'Port' :'50022' , 'ForwardX11' :'no' } print ('bitbucket.org' in conf)print ('bitbucket.com' in conf)print (conf['bitbucket.org' ]['user' ])print (conf['DEFAULT' ]['Compression' ])for key in conf['bitbucket.org' ]: print (key) print (conf.options('bitbucket.org' ))print (conf.items('bitbucket.org' ))print (conf.get('bitbucket.org' ,'compression' ))
增删改操作
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import configparserconf = configparser.ConfigParser() conf.read('config' ) conf.add_section('yuan' ) conf.remove_section('bitbucket.org' ) conf.remove_option('topsecret.server.com' ,'forwardx11' ) conf.set ('topsecret.server.com' ,'k1' ,'11111' ) conf.set ('yuan' ,'k2' ,'22222' ) conf.write(open ('config.new' ,'w' ))
logging模块 函数式简单配置 1 2 3 4 5 6 import logging logging.debug('debug message' ) logging.info('info message' ) logging.warning('warning message' ) logging.error('error message' ) logging.critical('critical message' )
默认情况下Python的logging模块将日志打印到了标准输出中,且只显示了大于等于WARNING级别的日志,这说明默认的日志级别设置为WARNING(日志级别等级CRITICAL > ERROR > WARNING > INFO > DEBUG),默认的日志格式为日志级别:Logger名称:用户输出消息。
1 2 3 4 5 6 7 8 9 10 11 12 13 import logginglogging.basicConfig(level=logging.DEBUG, format ='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s' , datefmt='%a, %d %b %Y %H:%M:%S' , filename='test.log' , filemode='w' ) logging.debug('debug message' ) logging.info('info message' ) logging.warning('warning message' ) logging.error('error message' ) logging.critical('critical message' )
参数解释
logging.basicConfig()函数中可通过具体参数来更改logging模块默认行为,可用参数有:
filename:用指定的文件名创建FiledHandler,这样日志会被存储在指定的文件中。
filemode:文件打开方式,在指定了filename时使用这个参数,默认值为“a”还可指定为“w”。
format:指定handler使用的日志显示格式。
datefmt:指定日期时间格式。
level:设置rootlogger(后边会讲解具体概念)的日志级别
stream:用指定的stream创建StreamHandler。可以指定输出到sys.stderr,sys.stdout或者文件(f=open- (‘test.log’,’w’)),默认为sys.stderr。若同时列出了filename和stream两个参数,则stream参数会被忽略。
format参数中可能用到的格式化串:
%(name)s Logger的名字
%(levelno)s 数字形式的日志级别
%(levelname)s 文本形式的日志级别
%(pathname)s 调用日志输出函数的模块的完整路径名,可能没有
%(filename)s 调用日志输出函数的模块的文件名
%(module)s 调用日志输出函数的模块名
%(funcName)s 调用日志输出函数的函数名
%(lineno)d 调用日志输出函数的语句所在的代码行
%(created)f 当前时间,用UNIX标准的表示时间的浮 点数表示
%(relativeCreated)d 输出日志信息时的,自Logger创建以 来的毫秒数
%(asctime)s 字符串形式的当前时间。默认格式是 “2003-07-08 16:49:45,896”。逗号后面的是毫秒
%(thread)d 线程ID。可能没有
%(threadName)s 线程名。可能没有
%(process)d 进程ID。可能没有
%(message)s用户输出的消息
logger对象配置 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import logginglogger = logging.getLogger() fh = logging.FileHandler('test.log' ,encoding='utf-8' ) ch = logging.StreamHandler() formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s' ) fh.setLevel(logging.DEBUG) fh.setFormatter(formatter) ch.setFormatter(formatter) logger.addHandler(fh) logger.addHandler(ch) logger.debug('logger debug message' ) logger.info('logger info message' ) logger.warning('logger warning message' ) logger.error('logger error message' ) logger.critical('logger critical message' )
logging库提供了多个组件:Logger、Handler、Filter、Formatter。Logger对象提供应用程序可直接使用的接口,Handler发送日志到适当的目的地,Filter提供了过滤日志信息的方法,Formatter指定日志显示格式。另外,可以通过:logger.setLevel(logging.Debug)设置级别,当然,也可以通过fh.setLevel(logging.Debug)单对文件流设置某个级别。
logger的配置文件 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 """ logging配置 """ import osimport logging.configstandard_format = '[%(asctime)s][%(threadName)s:%(thread)d][task_id:%(name)s][%(filename)s:%(lineno)d]' \ '[%(levelname)s][%(message)s]' simple_format = '[%(levelname)s][%(asctime)s][%(filename)s:%(lineno)d]%(message)s' id_simple_format = '[%(levelname)s][%(asctime)s] %(message)s' logfile_dir = os.path.dirname(os.path.abspath(__file__)) logfile_name = 'all2.log' if not os.path.isdir(logfile_dir): os.mkdir(logfile_dir) logfile_path = os.path.join(logfile_dir, logfile_name) LOGGING_DIC = { 'version' : 1 , 'disable_existing_loggers' : False , 'formatters' : { 'standard' : { 'format' : standard_format }, 'simple' : { 'format' : simple_format }, }, 'filters' : {}, 'handlers' : { 'console' : { 'level' : 'DEBUG' , 'class' : 'logging.StreamHandler' , 'formatter' : 'simple' }, 'default' : { 'level' : 'DEBUG' , 'class' : 'logging.handlers.RotatingFileHandler' , 'formatter' : 'standard' , 'filename' : logfile_path, 'maxBytes' : 1024 *1024 *5 , 'backupCount' : 5 , 'encoding' : 'utf-8' , }, }, 'loggers' : { '' : { 'handlers' : ['default' , 'console' ], 'level' : 'DEBUG' , 'propagate' : True , }, }, } def load_my_logging_cfg (): logging.config.dictConfig(LOGGING_DIC) logger = logging.getLogger(__name__) logger.info('It works!' ) if __name__ == '__main__' : load_my_logging_cfg() 注意: 1 、从字典加载配置:logging.config.dictConfig(settings.LOGGING_DIC) 2 、拿到logger对象来产生日志 logger对象都是配置到字典的loggers 键对应的子字典中的 按照我们对logging模块的理解,要想获取某个东西都是通过名字,也就是key来获取的 于是我们要获取不同的logger对象就是 logger=logging.getLogger('loggers子字典的key名' ) 但问题是:如果我们想要不同logger名的logger对象都共用一段配置,那么肯定不能在loggers子字典中定义n个key 'loggers' : { 'l1' : { 'handlers' : ['default' , 'console' ], 'level' : 'DEBUG' , 'propagate' : True , }, 'l2: { ' handlers': [' default', ' console' ], ' level': ' DEBUG', ' propagate': False, # 向上(更高level的logger)传递 }, ' l3': { ' handlers': [' default', ' console'], # ' level': ' DEBUG', ' propagate': True, # 向上(更高level的logger)传递 }, } #我们的解决方式是,定义一个空的key ' loggers': { ' ': { ' handlers': [' default', ' console'], ' level': ' DEBUG', ' propagate': True, }, } 这样我们再取logger对象时 logging.getLogger(__name__),不同的文件__name__不同,这保证了打印日志时标识信息不同,但是拿着该名字去loggers里找key名时却发现找不到,于是默认使用key=' '的配置
参考博客:
https://blog.csdn.net/pansaky/article/details/90710751
collections模块 在内置数据类型(dict、list、set、tuple)的基础上,collections模块还提供了几个额外的数据类型:Counter、deque、defaultdict、namedtuple和OrderedDict等。
namedtuple: 生成可以使用名字来访问元素内容的tuple
deque: 双端队列,可以快速的从另外一侧追加和推出对象
Counter: 计数器,主要用来计数
OrderedDict: 有序字典
defaultdict: 带有默认值的字典
namedtuple 1 2 3 4 from collections import namedtuplepoint = namedtuple('point' ,['x' ,'y' ]) p = point(1 ,2 ) print (p.x)
一个点的二维坐标就可以表示成,但是看到(1, 2),很难看出这个tuple是用来表示一个坐标的。
这时,namedtuple就派上了用场
deque 使用list存储数据时,按索引访问元素很快,但是插入和删除元素就很慢了,因为list是线性存储,数据量大的时候,插入和删除效率很低。
deque是为了高效实现插入和删除操作的双向列表,适合用于队列和栈
1 2 3 4 5 6 7 from collections import dequeq = deque(['a' ,'b' ,'c' ]) q.append('x' ) q.appendleft('y' ) print (q)
deque除了实现list的append()和pop()外,还支持appendleft()和popleft(),这样就可以非常高效地往头部添加或删除元素。
defaultdict 有如下值集合 [11,22,33,44,55,66,77,88,99,90…],将所有大于 66 的值保存至字典的第一个key中,将小于 66 的值保存至第二个key的值中。
即: {‘k1’: 大于66 , ‘k2’: 小于66}
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 以前的做法 li = [11 ,22 ,33 ,44 ,55 ,77 ,88 ,99 ,90 ] result = {} for row in li: if row < 66 : if 'key1' not in result: result['key1' ]=[] result['key1' ].append(row) else : if 'key2' not in result: result['key2' ]=[] result['key2' ].append(row) print (result)from collections import defaultdictli = [11 ,22 ,33 ,44 ,55 ,77 ,88 ,99 ,90 ] result=defaultdict(list ) for row in li: if row > 66 : result['key1' ].append(row) else : result['key2' ].append(row) print (result)
counter Counter类的目的是用来跟踪值出现的次数。它是一个无序的容器类型,以字典的键值对形式存储,其中元素作为key,其计数作为value。
1 2 3 4 from collections import Counterc = Counter('qazxswqazxswqazxswsxaqwsxaqws' ) print (c)
时间有关的模块 常用方法
time.sleep(secs)
time.time()
表示时间的三种方式
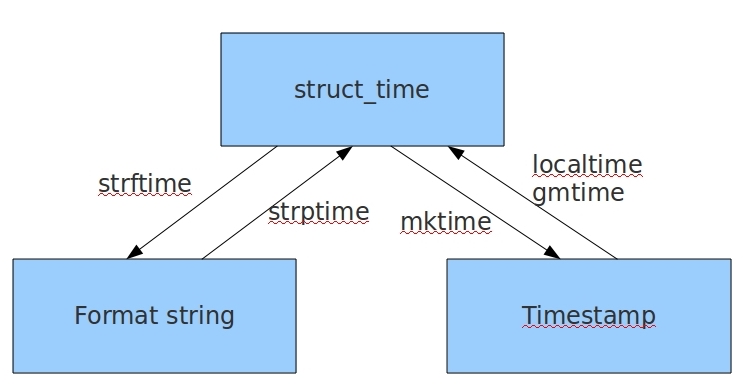
在Python中,通常有这三种方式来表示时间:时间戳、结构化的时间(struct_time)、格式化的时间字符串(Format String):
时间戳 (timestamp) :通常来说,时间戳表示的是从1970年1月1日00:00:00开始按秒计算的偏移量。我们运行“type(time.time())”,返回的是float类型。格式化的时间字符串(Format String): ‘1999-12-06’
%y
两位数的年份表示(00-99)
%Y
四位数的年份表示(000-9999)
%m
月份(01-12)
%d
月内中的一天(0-31)
%H
24小时制小时数(0-23)
%I
12小时制小时数(01-12)
%M
分钟数(00=59)
%S
秒(00-59)
%a
本地简化星期名称
%A
本地完整星期名称
%b
本地简化的月份名称
%B
本地完整的月份名称
%c
本地相应的日期表示和时间表示
%j
年内的一天(001-366)
%p
本地A.M.或P.M.的等价符
%U
一年中的星期数(00-53)星期天为星期的开始
%w
星期(0-6),星期天为星期的开始
%W
一年中的星期数(00-53)星期一为星期的开始
%x
本地相应的日期表示
%X
本地相应的时间表示
%Z
当前时区的名称
%%
%号本身
结构化时间(struct_time) :struct_time结构化时间共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天等)
索引(Index)
属性(Attribute)
值(Values)
0
tm_year(年)
比如2011
1
tm_mon(月)
1月12日
2
tm_mday(日)
1月31日
3
tm_hour(时)
0 - 23
4
tm_min(分)
0 - 59
5
tm_sec(秒)
0 - 60
6
tm_wday(weekday)
0 - 6(0表示周一)
7
tm_yday(一年中的第几天)
1 - 366
8
tm_isdst(是否是夏令时)
默认为0
1 2 3 4 5 6 7 8 9 10 11 import timeprint (time.time())print (time.strftime('%Y-%m-%d %X' ))print (time.strftime('%Y-%m-%d %H-%M-%S' ))print (time.localtime())
小结:时间戳是计算机能够识别的时间;时间字符串是人能够看懂的时间;元组则是用来操作时间的
几种格式之间的转换
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import timeft = time.strftime('%Y/%m/%d %H:%M:%S' ) st = time.strptime(ft,'%Y/%m/%d %H:%M:%S' ) print (st)t = time.mktime(st) print (t)t = time.time() st = time.localtime(t) print (st)ft = time.strftime('%Y/%m/%d %H:%M:%S' ,st) print (ft)
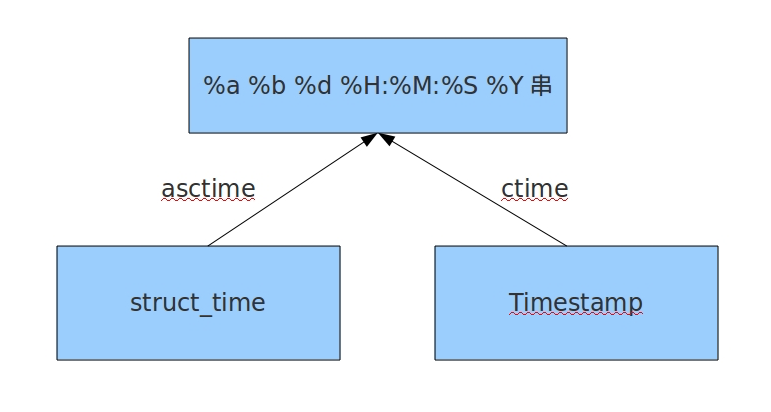
1 2 3 4 5 6 7 8 9 import timeprint (time.asctime(time.localtime(1550312090.4021888 )))print (time.ctime(1550312090.4021888 ))
计算时间差
1 2 3 4 5 6 7 8 9 import timestart_time=time.mktime(time.strptime('2017-09-11 08:30:00' ,'%Y-%m-%d %H:%M:%S' )) end_time=time.mktime(time.strptime('2019-09-12 11:00:50' ,'%Y-%m-%d %H:%M:%S' )) dif_time=end_time-start_time struct_time=time.gmtime(dif_time) print ('过去了%d年%d月%d天%d小时%d分钟%d秒' %(struct_time.tm_year-1970 ,struct_time.tm_mon-1 , struct_time.tm_mday-1 ,struct_time.tm_hour, struct_time.tm_min,struct_time.tm_sec))
datatime 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import datetimenow_time = datetime.datetime.now() print (datetime.datetime.now() + datetime.timedelta(weeks=3 )) print (datetime.datetime.now() + datetime.timedelta(weeks=-3 )) print (datetime.datetime.now() + datetime.timedelta(days=-3 )) print (datetime.datetime.now() + datetime.timedelta(days=3 )) print (datetime.datetime.now() + datetime.timedelta(hours=5 )) print (datetime.datetime.now() + datetime.timedelta(hours=-5 )) print (datetime.datetime.now() + datetime.timedelta(minutes=-15 )) print (datetime.datetime.now() + datetime.timedelta(minutes=15 )) print (datetime.datetime.now() + datetime.timedelta(seconds=-70 )) print (datetime.datetime.now() + datetime.timedelta(seconds=70 )) current_time = datetime.datetime.now() print (current_time.replace(year=1977 )) print (current_time.replace(month=1 )) print (current_time.replace(year=1989 ,month=4 ,day=25 )) print (datetime.date.fromtimestamp(1232132131 ))
random 用来生成随机数模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import randomprint (random.random()) print (random.uniform(1 ,3 )) print (random.randint(1 ,5 )) print (random.randrange(1 ,10 ,2 )) ret = random.choice([1 ,'23' ,[4 ,5 ]]) print (ret)a,b = random.sample([1 ,'23' ,[4 ,5 ]],2 ) print (a,b)item = [1 ,3 ,5 ,7 ,9 ] random.shuffle(item) print (item)
生成随机验证码
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 import randomdef v_code (): code = '' for i in range (5 ): num=random.randint(0 ,9 ) alf=chr (random.randint(65 ,90 )) add=random.choice([num,alf]) code="" .join([code,str (add)]) return code print (v_code())
os模块 os模块是与操作系统交互的一个接口
当前执行这个python文件的工作目录相关的工作路径
os.getcwd()
获取当前工作目录,即当前python脚本工作的目录路径
os.chdir(“dirname”)
改变当前脚本工作目录;相当于shell下cd
os.curdir
返回当前目录: (‘.’)
os.pardir
获取当前目录的父目录字符串名:(‘..’)
文件夹相关
os.makedirs(‘dirname1/dirname2’)
可生成多层递归目录
os.removedirs(‘dirname1’)
若目录为空,则删除,并递归到上一级目录,如若也为空,则删除,依此类推
os.mkdir(‘dirname’)
生成单级目录;相当于shell中mkdir dirname
os.rmdir(‘dirname’)
删除单级空目录,若目录不为空则无法删除,报错;相当于shell中rmdir dirname
os.listdir(‘dirname’)
列出指定目录下的所有文件和子目录,包括隐藏文件,并以列表方式打印
文件相关
os.remove()
删除一个文件
os.rename(“oldname”,”newname”)
重命名文件/目录
os.stat(‘path/filename’)
获取文件/目录信息
操作系统差异相关
os.sep
输出操作系统特定的路径分隔符,win下为”\“,Linux下为”/“
os.linesep
输出当前平台使用的行终止符,win下为”\t\n”,Linux下为”\n”
os.pathsep
输出用于分割文件路径的字符串 win下为;,Linux下为:
os.name
输出字符串指示当前使用平台。win->’nt’; Linux->’posix’
执行系统命令相关
os.system(“bash command”)
运行shell命令,直接显示
os.popen(“bash command).read()
运行shell命令,获取执行结果
os.environ
获取系统环境变量
path系列,和路径相关
os.path.abspath(path)
返回path规范化的绝对路径
os.path.split(path)
将path分割成目录和文件名二元组返回
os.path.dirname(path)
返回path的目录。其实就是os.path.split(path)的第一个元素
os.path.basename(path)
返回path最后的文件名。如何path以/或\结尾,那么就会返回空值,即os.path.split(path)的第二个元素。
os.path.exists(path)
如果path存在,返回True;如果path不存在,返回False
os.path.isabs(path)
如果path是绝对路径,返回True
os.path.isfile(path)
如果path是一个存在的文件,返回True。否则返回False
os.path.isdir(path)
如果path是一个存在的目录,则返回True。否则返回False
os.path.join(path1[, path2[, …]])
将多个路径组合后返回,第一个绝对路径之前的参数将被忽略
os.path.getatime(path)
返回path所指向的文件或者目录的最后访问时间
os.path.getmtime(path)
返回path所指向的文件或者目录的最后修改时间
os.path.getsize(path)
返回path的大小
1 2 3 4 5 6 import osprint (os.stat('.\config' ))
st_mode
inode 保护模式
st_ino
inode 节点号
st_dev
inode 驻留的设备
st_nlink
inode 的链接数
st_uid
所有者的用户ID
st_gid
所有者的组ID
st_size
普通文件以字节为单位的大小;包含等待某些特殊文件的数据
st_atime
上次访问的时间
st_mtime
最后一次修改的时间
st_ctime
由操作系统报告的”ctime”。在某些系统上(如Unix)是最新的元数据更改的时间,在其它系统上(如Windows)是创建时间(详细信息参见平台的文档)
sys模块 sys模块是与python解释器交互的一个接口
sys.argv
命令行参数List,第一个元素是程序本身路径
sys.exit(n)
退出程序,正常退出时exit(0),错误退出sys.exit(1)
sys.version
获取Python解释程序的版本信息
sys.path
返回模块的搜索路径,初始化时使用PYTHONPATH环境变量的值
sys.platform
返回操作系统平台名称
re模块 正则表达式 正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
元字符
匹配内容
\w
匹配字母(包含中文)或数字或下划线
\W
匹配非字母(包含中文)或数字或下划线
\s
匹配任意的空白符
\S
匹配任意非空白符
\d
匹配数字
\D
匹配非数字
\A
从字符串开头匹配
\z
匹配字符串的结束,如果是换行,只匹配到换行前的结果
\n
匹配一个换行符
\t
匹配一个制表符
^
匹配字符串的开始
$
匹配字符串的结尾
.
匹配任意字符,除了换行符,当re.DOTALL标记被指定时,则可以匹配包括换行符的任意字符。
[…]
匹配字符组中的字符
… 匹配除了字符组中的字符的所有字符
*
匹配0个或者多个左边的字符。
+
匹配一个或者多个左边的字符。
?
匹配0个或者1个左边的字符,非贪婪方式。
{n}
精准匹配n个前面的表达式。
{n,m}
匹配n到m次由前面的正则表达式定义的片段,贪婪方式
a
b
()
匹配括号内的表达式,也表示一个组
单字符匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import reprint (re.findall('\w' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\W' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\s' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\S' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\d' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\D' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\A上大' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('^上大' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('666\z' ,'上大人123asdfg%^&*(_ \t \n)666' ))print (re.findall('666\Z' ,'上大人123asdfg%^&*(_ \t \n)666' ))print (re.findall('666$' ,'上大人123asdfg%^&*(_ \t \n)666' ))print (re.findall('\n' ,'上大人123asdfg%^&*(_ \t \n)' ))print (re.findall('\t' ,'上大人123asdfg%^&*(_ \t \n)' ))
重复匹配 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import reprint (re.findall('a.b' , 'ab aab a*b a2b a牛b a\nb' ))print (re.findall('a.b' , 'ab aab a*b a2b a牛b a\nb' ,re.DOTALL))print (re.findall('a?b' , 'ab aab abb aaaab a牛b aba**b' ))print (re.findall('a*b' , 'ab aab aaab abbb' ))print (re.findall('ab*' , 'ab aab aaab abbbbb' ))print (re.findall('a+b' , 'ab aab aaab abbb' ))print (re.findall('a{2,4}b' , 'ab aab aaab aaaaabb' ))print (re.findall('a.*b' , 'ab aab a*()b' ))print (re.findall('a.*?b' , 'ab a1b a*()b, aaaaaab' ))print (re.findall('a.b' , 'a1b a3b aeb a*b arb a_b' ))print (re.findall('a[abc]b' , 'aab abb acb adb afb a_b' ))print (re.findall('a[0-9]b' , 'a1b a3b aeb a*b arb a_b' ))print (re.findall('a[a-z]b' , 'a1b a3b aeb a*b arb a_b' ))print (re.findall('a[a-zA-Z]b' , 'aAb aWb aeb a*b arb a_b' ))print (re.findall('a[0-9][0-9]b' , 'a11b a12b a34b a*b arb a_b' ))print (re.findall('a[*-+]b' ,'a-b a*b a+b a/b a6b' ))print (re.findall('a[-*+]b' ,'a-b a*b a+b a/b a6b' ))print (re.findall('a[^a-z]b' , 'acb adb a3b a*b' ))print (re.findall('(.*?)_66' , 'cs_66 zhao_66 日天_66' ))print (re.findall('href="(.*?)"' ,'<a href="http://www.baidu.com">点击</a>' ))print (re.findall('compan(y|ies)' ,'Too many companies have gone bankrupt, and the next one is my company' ))print (re.findall('compan(?:y|ies)' ,'Too many companies have gone bankrupt, and the next one is my company' ))
常用方法举例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import reprint (re.findall('a' ,'aghjmnbghagjmnbafgv' ))print (re.search('Eagle' , 'welcome to Eagleslab' ))print (re.search('Eagle' , 'welcome to Eagleslab' ).group())print (re.match ('sb|chensong' , 'chensong 66 66 demon 日天' ))print (re.match ('chensong' , 'chensong 66 66 barry 日天' ).group())print (re.split('[::,;;,]' ,'1;3,c,a:3' ))print (re.sub('镇江' ,'英格科技' ,'欢迎来到镇江' ))obj = re.compile ('\d{2}' ) print (obj.search('abc123eeee' ).group())print (obj.findall('1231232aasd' ))ret = re.finditer('\d' ,'asd123affess32432' ) print (ret)print (next (ret).group())print (next (ret).group())print ([i.group() for i in ret])
命名分组举例 命名分组匹配
1 2 3 4 5 6 7 8 9 10 11 import reret = re.search("<(?P<tag_name>\w+)>\w+</(?P=tag_name)>" ,"<h1>hello</h1>" ) print (ret.group('tag_name' ))print (ret.group())ret = re.search(r"<(\w+)>\w+</\1>" ,"<h1>hello</h1>" ) print (ret.group(1 ))print (ret.group())
shutil 高级的 文件、文件夹、压缩包 处理模块
shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中
1 2 3 import shutilshutil.copyfileobj(open ('config' ,'r' ),open ('config.new' ,'w' ))
shutil.copyfile(src, dst) 拷贝文件
1 2 3 import shutilshutil.copyfile('config' ,'config1' )
shutil.copymode(src, dst) 仅拷贝权限。内容、组、用户均不变
1 2 3 import shutilshutil.copymode('config' ,'config1' )
shutil.copystat(src, dst) 仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
1 2 3 import shutilshutil.copystat('config' ,'config1' )
shutil.copy(src, dst) 拷贝文件和权限
1 2 3 import shutilshutil.copy('config' ,'config1' )
shutil.ignore_patterns(*patterns) shutil.copytree(src, dst, symlinks=False, ignore=None) 递归的去拷贝文件夹
1 2 3 4 5 6 7 8 import shutilshutil.copytree('folder1' , 'folder2' , ignore=shutil.ignore_patterns('*.pyc' , 'tmp*' )) shutil.copytree('f1' , 'f2' , symlinks=True , ignore=shutil.ignore_patterns('*.pyc' , 'tmp*' ))
shutil.rmtree(path[, ignore_errors[, onerror]]) 递归的去删除文件
1 2 3 import shutilshutil.rmtree('folder1' )
shutil.move(src, dst) 递归的去移动文件,它类似mv命令,其实就是重命名。
1 2 3 import shutilshutil.move('folder1' , 'folder3' )
创建压缩包并返回文件路径,例如:zip、tar
base_name: 压缩包的文件名,也可以是压缩包的路径。只是文件名时,则保存至当前目录,否则保存至指定路径,
如 data_bak =>保存至当前路径
如:/tmp/data_bak =>保存至/tmp/
format: 压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir: 要压缩的文件夹路径(默认当前目录)
owner: 用户,默认当前用户
group: 组,默认当前组
logger: 用于记录日志,通常是logging.Logger对象
1 2 3 4 5 6 7 8 import shutilret = shutil.make_archive("data_bak" , 'gztar' , root_dir='/data' ) import shutilret = shutil.make_archive("/tmp/data_bak" , 'gztar' , root_dir='/data' )
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import zipfilez = zipfile.ZipFile('laxi.zip' , 'w' ) z.write('a.log' ) z.write('data.data' ) z.close() z = zipfile.ZipFile('laxi.zip' , 'r' ) z.extractall(path='.' ) z.close() import tarfilet = tarfile.open ('/tmp/egon.tar' ,'w' ) t.add('/test1/a.py' ,arcname='a.bak' ) t.add('/test1/b.py' ,arcname='b.bak' ) t.close() t = tarfile.open ('/tmp/egon.tar' ,'r' ) t.extractall('/egon' ) t.close()
异常处理 异常和错误 异常种类 在python中不同的异常可以用不同的类型(python中统一了类与类型,类型即类)去标识,不同的类对象标识不同的异常,一个异常标识一种错误
1 2 3 4 5 6 7 8 9 10 l=['eagle' ,'aa' ] l[3 ] dic={'name' :'eagle' } dic['age' ] s='hello' int (s)
常见异常
AttributeError
试图访问一个对象没有的属性,比如foo.x,但是foo没有属性x
IOError
输入/输出异常;基本上是无法打开文件
ImportError
无法引入模块或包;基本上是路径问题或名称错误
IndentationError
语法错误(的子类) ;代码没有正确对齐
IndexError
下标索引超出序列边界,比如当x只有三个元素,却试图访问x[5]
KeyError
试图访问字典里不存在的键
KeyboardInterrupt
Ctrl+C被按下
NameError
使用一个还未被赋予对象的变量
SyntaxError
Python代码非法,代码不能编译(个人认为这是语法错误,写错了)
TypeError
传入对象类型与要求的不符合
UnboundLocalError
试图访问一个还未被设置的局部变量,基本上是由于另有一个同名的全局变量,导致你以为正在访问它
ValueError
传入一个调用者不期望的值,即使值的类型是正确的
其他错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 ArithmeticError AssertionError AttributeError BaseException BufferError BytesWarning DeprecationWarning EnvironmentError EOFError Exception FloatingPointError FutureWarning GeneratorExit ImportError ImportWarning IndentationError IndexError IOError KeyboardInterrupt KeyError LookupError MemoryError NameError NotImplementedError OSError OverflowError PendingDeprecationWarning ReferenceError RuntimeError RuntimeWarning StandardError StopIteration SyntaxError SyntaxWarning SystemError SystemExit TabError TypeError UnboundLocalError UnicodeDecodeError UnicodeEncodeError UnicodeError UnicodeTranslateError UnicodeWarning UserWarning ValueError Warning ZeroDivisionError
异常处理
python解释器检测到错误,触发异常(也允许程序员自己触发异常)
程序员编写特定的代码,专门用来捕捉这个异常(这段代码与程序逻辑无关,与异常处理有关)
如果捕捉成功则进入另外一个处理分支,执行你为其定制的逻辑,使程序不会崩溃,这就是异常处理 首先须知,异常是由程序的错误引起的,语法上的错误跟异常处理无关,必须在程序运行前就修正
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 num1=input ('>>: ' ) if num1.isdigit(): int (num1) elif num1.isspace(): print ('输入的是空格,就执行我这里的逻辑' ) elif len (num1) == 0 : print ('输入的是空,就执行我这里的逻辑' ) else : print ('其他情情况,执行我这里的逻辑' ) ''' 问题一: 使用if的方式我们只为第一段代码加上了异常处理,但这些if,跟你的代码逻辑并无关系,这样你的代码会因为可读性差而不容易被看懂 问题二: 这只是我们代码中的一个小逻辑,如果类似的逻辑多,那么每一次都需要判断这些内容,就会倒置我们的代码特别冗长。 ''' try : num = input ("<<:" ) int (num) except : print ('你输入的是非数字' ) finally : print ('程序结束' )
总结:
if判断式的异常处理只能针对某一段代码,对于不同的代码段的相同类型的错误你需要写重复的if来进行处理。
在你的程序中频繁的写与程序本身无关,与异常处理有关的if,会使得你的代码可读性极其的差
if是可以解决异常的,只是存在1,2的问题,所以,千万不要妄下定论if不能用来异常处理。
1 2 3 4 5 6 7 8 9 10 11 def test (): print ('test.runing' ) choice_dic = { '1' :test } while True : choice = (input ('>>: ' ).strip()) if not choice or choice not in choice_dic:continue choice_dic[choice]()
python:为每一种异常定制了一个类型,然后提供了一种特定的语法结构用来进行异常处理
基本语法 1 2 3 4 try : 被检测的代码块 except 异常类型: try 中一旦检测到异常,就执行这个位置的逻辑
将文件的每一行变成一个迭代器,然后读出来
1 2 3 4 5 6 7 f = open ('a.txt' ) g = (line.strip() for line in f) for line in g: print (line) else : f.close()
但是如果超出了迭代器的范围就会出现StopIteration错误
使用异常处理
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 try : f = open ('a.txt' ) g = (line.strip() for line in f) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) print (next (g)) except StopIteration: f.close() print ('读取出错' )
异常类只能用来处理指定的异常情况 1 2 3 4 5 s1 = 'hello' try : int (s1) except IndexError as e: print e
多分支 主要是用来针对不同的错误情况进行错误处理
1 2 3 4 5 6 7 8 9 s1 = 'hello' try : int (s1) except IndexError as e: print (e) except KeyError as e: print (e) except ValueError as e: print (e)
万能异常:Exception 1 2 3 4 5 s1 = 'hello' try : int (s1) except Exception as e: print (e)
多分支加万能异常
1 2 3 4 5 6 7 8 9 10 11 s1 = 'hello' try : int (s1) except IndexError as e: print (e) except KeyError as e: print (e) except ValueError as e: print (e) except Exception as e: print (e)
其他异常情况 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 s1 = '10' try : int (s1) except IndexError as e: print (e) except KeyError as e: print (e) except ValueError as e: print (e) except Exception as e: print (e) else : print ('try内代码块没有异常则执行我' ) finally : print ('无论异常与否,都会执行该模块,通常是进行清理工作' )
主动触发异常 1 2 3 4 try : raise TypeError('类型错误' ) except Exception as e: print (e)
自定义异常 1 2 3 4 5 6 7 8 9 10 class EvaException (BaseException ): def __init__ (self,msg ): self .msg=msg def __str__ (self ): return self .msg try : raise EvaException('类型错误' ) except EvaException as e: print (e)
断言 表达式位True时,程序继续运行,表达式为False时程序终止运行,并报AssertionError错误
1 2 assert 1 == 1 assert 1 == 2
try..except的方式比较if的方式的好处
把错误处理和真正的工作分开来
代码更易组织,更清晰,复杂的工作任务更容易实现
毫无疑问,更安全了,不至于由于一些小的疏忽而使程序意外崩溃了
垃圾回收机制 一、引用计数器 1.1环状的双向链表(Refchain)
在python程序中,创建的任何对象都会放在refchain的双向链表中
例如:
1 2 3 name = "小猪佩奇" # 字符串对象 age = 18 # 整形对象 hobby = ["吸烟","喝酒","烫头"] # 列表对象
这些对象都会放到这些双向链表当中,也就是帮忙维护了python中所有的对象。 也就是说如果你得到了refchain,也就得到了python程序中的所有对象。
1.2不同类型对象的存放形式 刚刚提到了所有的对象都存放在环状的双向链表 中,而不同类型的对象存放在双向链表中既有一些共性特征 也有一些不同特征 。
1 2 3 4 5 6 7 8 9 10 11 # name = "小猪佩奇" # 创建这个对象时,内部会创建一些数据,并且打包在一起 # 哪些数据:【指向上一个对象的指针、指向下一个对象的指针、类型(这里为字符串)、引用的个数】 """ 引用的个数: 比如 name = '小猪佩奇' ,会给“小猪佩奇”开辟一个内存空间用来存放到双向链表中。 这时候如果有 new = name,不会创建两个“小猪佩奇”,而是将new指向之前的那个小猪佩奇, 而引用的个数变为2,也就是"小猪佩奇"这个对象被引用了两次。 """
1 2 3 4 5 # 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数】 age = 18 # 整形对象 # 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数】 hobby = ["吸烟","喝酒","烫头"] # 列表对象
1 2 3 4 5 # 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数、val=18】 age = 18 # 整形对象 # 内部会创建一些数据,【指向上一个对象的指针、指向下一个对象的指针、类型、引用的个数、items=元素、元素的个数】 hobby = ["抽烟","喝酒","烫头"] # 列表对象
所以在python中创建的对象会加到环形双向链表中,但是每一种类型的数据对象在存到链表中时,所存放的数据个数可能是不同的(有相同点有不同点)。
两个重要的结构体 Python解释器由c语言开发完成,py中所有的操作最终都由底层的c语言来实现并完成,所以想要了解底层内存管理需要结合python源码来进行解释。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 #define PyObject_HEAD PyObject ob_base ; #define PyObject_VAR_HEAD PyVarObject ob_base; //宏定义,包含上一个、下一个,用于构造双向链表用。(放到refchain链表中时,要用到) #define _PyObject_HEAD_EXTRA \ struct _object *_ob_next; \ struct _object *_ob_prev; typedef struct _object { _PyObject_HEAD_EXTRA //用于构造双向链表 Py_ssize_t ob_refcnt; //引用计数器 struct _typeobject *ob_type; //数据类型 } PyObject; typedef struct { PyObject ob_base; // PyObject对象 Py_ssize_t ob_size; /* Number of items in variable part, 即:元素个数*/ } PyVarObject;
在C源码中如何体现每个对象中都有的相同的值:PyObject结构体(4个值:_ob_next、_ob_prev、ob_refcnt、*ob_type) 9-13行 定义了一个结构体,第10行实际上就是6,7两行,用来存放前一个对象,和后一个对象的位置。
这个结构体可以存贮四个值(这四个值是对象都具有的 )。
在C源码中如何体现由多个元素组成的对象:PyObject + ob_size(元素个数)
15-18行又定义了一个结构体,第16行相当于代指了9-13行中的四个数据。
而17行又多了一个数据字段,叫做元素个数,这个结构体。
以上源码是Python内存管理中的基石,其中包含了:
类型封装的结构体 在我们了解了这两个结构体,现在我们来看看每一个数据类型都封装了哪些值:
1 2 3 4 typedef struct { PyObject_HEAD # 这里相当于代表基础的4个值 double ob_fval; } PyFloatObject;
例:
1 2 3 4 5 6 7 8 data = 3.14 内部会创建: _ob_next = refchain中的上一个对象 _ob_prev = refchain中的后一个对象 ob_refcnt = 1 引用个数 ob_type= float 数据类型 ob_fval = 3.14
1 2 3 4 5 6 7 8 9 struct _longobject { PyObject_VAR_HEAD digit ob_digit[1]; }; // longobject.h /* Long (arbitrary precision) integer object interface */ typedef struct _longobject PyLongObject; /* Revealed in longintrepr.h */
道理都是相同的,第2行代指第二个重要的结构体,第三行是int形特有的值,总结下来就是这个结构体中有几个值,那么创建这个类型对象的时候内部就会创建几个值。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 typedef struct { PyObject_VAR_HEAD /* Vector of pointers to list elements. list[0] is ob_item[0], etc. */ PyObject **ob_item; /* ob_item contains space for 'allocated' elements. The number * currently in use is ob_size. * Invariants: * 0 <= ob_size <= allocated * len(list) == ob_size * ob_item == NULL implies ob_size == allocated == 0 * list.sort() temporarily sets allocated to -1 to detect mutations. * * Items must normally not be NULL, except during construction when * the list is not yet visible outside the function that builds it. */ Py_ssize_t allocated; } PyListObject;
1 2 3 4 5 6 7 8 9 typedef struct { PyObject_VAR_HEAD PyObject *ob_item[1]; /* ob_item contains space for 'ob_size' elements. * Items must normally not be NULL, except during construction when * the tuple is not yet visible outside the function that builds it. */ } PyTupleObject;
1 2 3 4 5 6 typedef struct { PyObject_HEAD Py_ssize_t ma_used; PyDictKeysObject *ma_keys; PyObject **ma_values; } PyDictObject;
到这里我们就学到了什么是环状双向链表,以及双向链表中存放的每一种数据类型的对象都是怎样的。
1.3引用计数器 1 2 3 v1 = 3.14 v2 = 999 v3 = (1,2,3)
当python程序运行时,会根据数据类型的不同,找到其对应的结构体,根据结构体中的字段,来进行创建相关的数据,然后将对象添加到refchain双向链表中。 为了体现我们看过源码的牛逼之处,我们还可以进一步理解。
在C源码中有两个关键的结构体:PyObject、PyvarObject
PyObject(存储是上一个对象,下一个对象,类型,引用的个数,是每一个对象都具有的)。
PyvarObject(存储的是由多个元素组成的类型数据具有的值,例如字符串,int)。
\1. python3中没有long类型,只有int类型,但py3内部的int是基于long实现。
\2. python3中对int长度没有限制,其内部使用由多个元素组成的类似于“字符串”的机制来存储的。 每个对象中都有ob_refcnt ,它就是引用计数器,创建时默认是1,当有其他变量重新引用的时候,引用计数器就会发生变化。
计数器增加 当发生以下四种情况的时候,该对象的引用计数器+1 :**
1 2 3 4 5 6 a=14 # 对象被创建 b=a # 对象被引用 func(a) # 对象被作为参数,传到函数中 List=[a,"a","b",2] # 对象作为一个元素,存储在容器中 b = 9999 # 引用计数器的值为1 c = b # 引用计数器的值为2
计数器减小 当发生以下四种情况时,该对象的引用计数器**-1**
1 2 3 4 5 6 7 8 9 10 11 12 当该对象的别名被显式销毁时 del a 当该对象的引别名被赋予新的对象, a=26 一个对象离开它的作用域,例如 func函数执行完毕时,函数里面的局部变量的引用计数器就会减一(但是全局变量不会) 将该元素从容器中删除时,或者容器被销毁时。 a = 999 b = a # 当前计数器为2 del b # 删除变量b:b对应的对象的引用计数器-1 (此时计数器为1) del a # 删除变量a:a对应的对象的引用计数器-1 (此时引用计数器为0) 当引用计数器为0 时,意味着没有人再使用这个对象,这个对象就变成垃圾,垃圾回收。 回收:1.对象从refchain的链表移除。 2.将对象进行销毁,内存归还给操作系统,可用内存就增加。
当引用计数器 为0 时,意味着没有人再使用这个对象,这个对象就变成垃圾,垃圾回收。 回收:1.对象从refchain的链表移除。 2.将对象进行销毁,内存归还给操作系统,可用内存就增加 。
以上就是引用计数器大体上的机制,但是后面的缓存机制学习完之后我们才会进一步理解,这里不是简单的说计数器等于0就销毁,内部还有一定的缓冲,目前就简单理解成计数器为0,我们就进行垃圾回收。
例子 1 2 3 4 5 6 7 a = "雷霆嘎巴" # 创建对象并初始话引用计数器为1 b = a # 计数器发生变化 c = a d = a e = a f = "小猪佩奇" # 创建对象并初始话引用计数器为1
当我们将”雷霆嘎巴”的对象的引用计数器减小至0时,就将其移除,并且相邻两边直接连接。
1.4循环引用问题 一种编程语言利用引用计数器实现垃圾管理和回收,已经是比较完美的了,只要计数器为0就回收,不为0就不回收,即简单明了,又能实现垃圾管理。
但是如果真正这样想就太单纯了,因为,仅仅利用引用计数器实现垃圾管理和回收,就会存在一个BUG,就是循环引用问题。
比如:
1 2 3 4 5 6 7 8 9 v1 = [1,2,3] # refchain中创建一个列表对象,由于v1=对象,所以列表引对象用计数器为1. v2 = [4,5,6] # refchain中再创建一个列表对象,因v2=对象,所以列表对象引用计数器为1. v1.append(v2) # 把v2追加到v1中,则v2对应的[4,5,6]对象的引用计数器加1,最终为2. v2.append(v1) # 把v1追加到v1中,则v1对应的[1,2,3]对象的引用计数器加1,最终为2. del v1 # 引用计数器-1 del v2 # 引用计数器-1 最终v1,v2引用计数器都是1
两个引用计数器现在都是1,那么它们都不是垃圾所以都不会被回收,但如果是这样的话,我们的代码就会出现问题。
我们删除了v1和v2,那么就没有任何变量指向这两个列表,那么这两个列表之后程序运行的时候都无法再使用,但是这两个列表的引用计数器都不为0,所以不会被当成垃圾进行回收,所以这两个列表就会一直存在在我们的内存中,永远不会销毁,当这种代码越来越多时,我们的程序一直运行,内存就会一点一点被消耗,然后内存变满,满了之后就爆栈了。这时候如果重新启动程序或者电脑,这时候程序又会正常运行,其实这就是因为循环引用导致数据没有被及时的销毁导致了内存泄漏。
1.5总结 优点
简单
实时性:一旦没有引用,内存就直接释放了。 不用像其他机制等到特定时机。实时性还带来一个好处:处理回收内存的时间分摊到了平时
缺点
维护引用计数消耗资源
循环引用 对于如今的强大硬件,缺点1尚可接受,但是循环引用导致内存泄露,注定python还将引入新的回收机制(标记清除和分代收集)。
二、标记清除 2.1引入目的 为了解决循环引用的不足,python的底层不会单单只用引用计数器,引入了一个机制叫做标记清楚。
2.2实现原理 在python的底层中,再去维护一个链表,这个链表中专门放那些可能存在循环引用的对象。
那么哪些情况可能导致循环引用的情况发生?
就是那些元素里面可以存放其他元素的元素。(list/dict/tuple/set,甚至class)
例如:
第二个链表 只存储 可能是循环引用的对象 。
维护两个链表的作用是,在python内部某种情况下,会去扫描可能存在循环引用的链表 中的每个元素,在循环一个列表的元素时,由于内部还有子元素 ,如果存在循环引用(v1 = [1,2,3,v2]和v2 = [4,5,6,v1]),比如从v1的子元素中找到了v2,又从v2的子元素中找到了v1,那么就检查到循环引用,如果有循环引用,就让双方的引用计数器各自-1,如果是0则垃圾回收。
2.3标记清除算法 【标记清除(Mark—Sweep)】算法是一种基于追踪回收(tracing GC)技术实现的垃圾回收算法。它分为两个阶段:第一阶段是标记阶段,GC会把所有的『活动对象』打上标记,第二阶段是把那些没有标记的对象『非活动对象』进行回收。那么GC又是如何判断哪些是活动对象哪些是非活动对象的呢?
对象之间通过引用(指针)连在一起,构成一个有向图,对象构成这个有向图的节点,而引用关系构成这个有向图的边 。从根对象(root object)出发,沿着有向边遍历对象,可达的(reachable)对象标记为活动对象,不可达的对象就是要被清除的非活动对象 。根对象就是全局变量、调用栈、寄存器。
在上图中,我们把小黑点视为全局变量,也就是把它作为root object,从小黑点出发,对象1可直达,那么它将被标记,对象2、3可间接到达也会被标记,而4和5不可达,那么1、2、3就是活动对象,4和5是非活动对象会被GC回收。
寻找跟对象(root object)的集合作为垃圾检测动作的起点,跟对象也就是一些全局引用和函数栈中的引用,这些引用所指向的对象是不可被删除的。
从root object集合出发,沿着root object集合中的每一个引用,如果能够到达某个对象,则说明这个对象是可达的,那么就不会被删除,这个过程就是垃圾检测阶段。
当检测阶段结束以后,所有的对象就分成可达和不可达两部分,所有的可达对象都进行保留,其它的不可达对象所占用的内存将会被回收,这就是垃圾回收阶段。(底层采用的是链表 将这些集合的对象连接在一起)。
三、分代回收 3.1引入目的 问题:
什么时候扫描去检测循环引用?
标记和清除的过程效率不高 。清除非活动的对象前它必须顺序扫描整个堆内存,哪怕只剩下小部分活动对象也要扫描所有对象。 为了解决上述的问题,python又引入了分代回收。
3.2原理 将第二个链表(可能存在循环引用的链表),维护成3个环状双向的链表:
0代: 0代中对象个数达到700个,扫描一次。
1代: 0代扫描10次,则1代扫描1次。
2代: 1代扫描10次,则2代扫描1次。
1 2 3 4 5 6 7 8 // 分代的C源码 #define NUM_GENERATIONS 3 struct gc_generation generations[NUM_GENERATIONS] = { /* PyGC_Head, threshold, count */ {{(uintptr_t)_GEN_HEAD(0), (uintptr_t)_GEN_HEAD(0)}, 700, 0}, // 0代 {{(uintptr_t)_GEN_HEAD(1), (uintptr_t)_GEN_HEAD(1)}, 10, 0}, // 1代 {{(uintptr_t)_GEN_HEAD(2), (uintptr_t)_GEN_HEAD(2)}, 10, 0}, // 2代 };
例:
当我们创建一个对象val = 19,那么它只会加到refchain链表中。
当我们创建一个对象v1 = [11,22],除了加到refchain,那么它会加到0代链表中去。
如果再创建一个对象v2 = [33,44],那么它还是往0代添加。
直到0代中的个数达到700之后,就会对0代中的所有元素进行一次扫描,扫描时如果检测出是循环引用那么引用计数器就自动-1,然后判断引用计数器是否为0,如果为0,则为垃圾就进行回收。不是垃圾的话,就对该数据进行升级,从0代升级到1代,这个时候0代就是空,1代就会记录一下0代已经扫描1次,然后再往0代中添加对象直到700再进行一次扫描,不停反复,直到0代扫描了10次,才会对1代进行1次扫描。
分代回收解决了标记清楚时什么时候扫描的问题,并且将扫描的对象分成了3级,以及降低扫描的工作量,提高效率。
3.3弱代假说 为什么要按一定要求进行分代扫描?
这种算法的根源来自于弱代假说 (weak generational hypothesis)。
这个假说由两个观点构成:首先是年轻的对象通常死得也快,而老对象则很有可能存活更长的时间。
假定现在我用Python创建一个新对象 n1=”ABC”
根据假说,我的代码很可能仅仅会使用ABC很短的时间。这个对象也许仅仅只是一个方法中的中间结果,并且随着方法的返回这个对象就将变成垃圾了。大部分的新对象都是如此般地很快变成垃圾。然而,偶尔程序会创建一些很重要的,存活时间比较长的对象,例如web应用中的session变量或是配置项。
频繁的处理零代链表中的新对象,可以将让Python的垃圾收集器把时间花在更有意义的地方 :它处理那些很快就可能变成垃圾的新对象。同时只在很少的时候,当满足一定的条件,收集器才回去处理那些老变量。
四、总结 将上面三个点学习之后,基本上应付面试没有太大问题了。
在python中维护了refchain的双向环状链表,这个链表中存储创建的所有对象,而每种类型的对象中,都有一个ob_refcnt引用计数器的值,它维护者引用的个数+1,-1,最后当引用计数器变为0时,则进行垃圾回收(对象销毁、refchain中移除)。
但是,在python中对于那些可以有多个元素组成的对象,可能会存在循环引用的问题,并且为了解决这个问题,python又引入了标记清除和分代回收,在其内部维护了4个链表,分别是:
refchain
2代,10次
1代,10次
0代,700个 在源码内部,当达到各自的条件阈值时,就会触发扫描链表进行标记清除的动作(如果有循环引用,引用计数器就各自-1)。
到这里我们只需要把这些给面试官说完就可以了。
————————————————
但是,源码内部在上述的流程中提出了优化机制,就是缓存机制。
五、缓存机制 缓存在python中分为两大类
5.1池 在python中为了避免重复创建和销毁一些常见对象,维护池。
例:
1 2 3 4 5 v1 = 7 v2 = 9 v3 = 9 # 按理说在python中会创建3个对象,都加入refchain中。
然而python在启动解释器时,python认为-5、-4、….. 、256,bool、一定规则的字符串,这些值都是常用的值,所以就会在内存中帮你先把这些值先创建好,接下来进行验证:
1 2 3 4 5 6 7 8 9 10 11 12 # 启动解释器时,python内部帮我们创建-5、-4、...255、256的整数和一定规则的字符串 v1 = 9 # 内部不会开辟内存,直接去池中获取 v2 = 9 # 同上,都是去数据池里直接拿9,所以v1和v2指向的内存地址是一样的 print(id(v1),id(v2)) v3 = 256 # 内部不会开辟内存,直接去池中获取 v4 = 256 # 同上,都是去数据池里直接拿256,所以v3和v4指向的内存地址是一样的 print(id(v3),id(4)) v5 = 257 v6 = 257 print(id(v5),id(v6))
排查原因:版本不同,小数据池扩大。 在交互模式下返回得结果符合预期,文件模式的情况下
问题:为什么交互模式和命令模式结果有区别?
答:因为代码块的缓存机制。
什么是代码块? 一个模块、一个函数、一个类、一个文件等都是一个代码块;交互式命令下,一行就是一个代码块。
同一个代码块内的缓存机制(字符串驻留机制)
机制内容:Python在执行同一个代码块的初始化对象的命令时,会检查是否其值是否已经存在,如果存在,会将其重用,即将两个变量指向同一个对象。换句话说:执行同一个代码块时,遇到初始化对象的命令时,他会将初始化的这个变量与值存储在一个字典中,在遇到新的变量时,会先在字典中查询记录,如果有同样的记录那么它会重复使用这个字典中的之前的这个值。所以在用命令模式执行时(同一个代码块)会把i1、i2两个变量指向同一个对象,满足缓存机制则他们在内存中只存在一个,即:id相同。
适用对象: int(float),str,bool。
int(float):任何数字 在同一代码块下都会复用。
bool:True和False在字典中会以1,0 方式存在,并且复用。
str:几乎所有的字符串 都会符合字符串驻留机制
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 # 同一个代码块内的缓存机制————任何数字在同一代码块下都会复用 i1 = 1000 i2 = 1000 print(id(i1)) print(id(i2)) 输出结果: # 同一个代码块内的缓存机制————几乎所有的字符串都会符合缓存机制 s1 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中国' s2 = 'hfdjka6757fdslslgaj@!#fkdjlsafjdskl;fjds中国' print(id(s1)) print(id(s2)) 输出结果: # 同一个代码块内的缓存机制————容器类型数据,一般指向的内存地址一定不同 t1 = (1,2,3) t2 = (1,2,3) l1 = [1,2,3] l2 = [1,2,3] print(id(t1)) print(id(t2)) print(id(l1)) print(id(l2)) 输出结果:
不同代码块间的缓存机制(小数据池、小整数缓存机制、小整数驻留机制)
适用对象: int(float),str,bool
具体细则:**-5~256数字,bool,满足一定规则的字符串**。
优点:提升性能,节省内存。
Python自动将-5~256的整数进行了缓存,当你将这些整数赋值给变量时,并不会重新创建对象,而是使用已经创建好的缓存对象。
python会将一定规则的字符串在字符串驻留池中,创建一份,当你将这些字符串赋值给变量时,并不会重新创建对象, 而是使用在字符串驻留池中创建好的对象。
其实,无论是缓存还是字符串驻留池,都是python做的一个优化,就是将~5-256的整数,和一定规则的字符串,放在一个‘池’(容器,或者字典)中,无论程序中那些变量指向这些范围内的整数或者字符串,那么他直接在这个‘池’中引用,言外之意,就是内存中之创建一个。
1 2 3 4 5 6 7 8 9 10 11 12 # 创建文件1: file1 def A(): b = 1 print(id(b)) # 创建文件2: file2 from file1 import A a = 1 print(id(a)) A()
总结一下就是,同一个代码块中(交互模式中的)因为字符串驻留机制,int(float),str,bool这些数据类型,只要对象相同,那么内存地址共享。 而不同代码块中只有引用对象为 -5~256整数,bool,满足一定规则的字符串, 才会有内存共享,即id相同。
并且这些python编辑器初始化的数据,他们的引用计数器永远不会为0,在初始化的时候就会将引用计数器默认设置为1。
5.2 free_list 当一个对象的引用计数器为0的时候,按理说应该回收,但是在python内部为了优化,不会去回收,而是将对象添加到free_list链表中当作缓存。以后再去创建对象时就不再重新开辟内存,而是直接使用free_list。
1 2 3 4 v1 = 3.14 # 创建float型对象,加入refchain,并且引用计数器的值为1 del v1 #refchain中移除,按理说应该销毁,但是python会将对象添加到free_list中。 v2 = 9.999 # 就不会重新开辟内存,去free_list中获取对象,对象内部数据初始化,再放到refchain中。
但是free_list也是有容量的,不是无限收纳, 假设默认数量为80,只有当free_list满的时候,才会直接去销毁。 代表性的有float/list/tuple/dict,这些数据类型都是以free_list方式来进行回收的。
缓存列表对象的创建源码:
总结一下,就是引用计数器为0的时候,有的是直接销毁,而有些需要先加入缓存当中的。
每个数据类型的缓存链表源码详见:[https://pythonav.com/wiki/detail/6/88/#2.4%20int%E7%B1%BB%E5%9E%8B](https://pythonav.com/wiki/detail/6/88/#2.4 int类型)